
将 Flink 应用于用户画像的场景,既能轻松应对大量的计算量,也能提供实时的计算结果,还能避免开发同学用编程的方式开发数据清洗任务。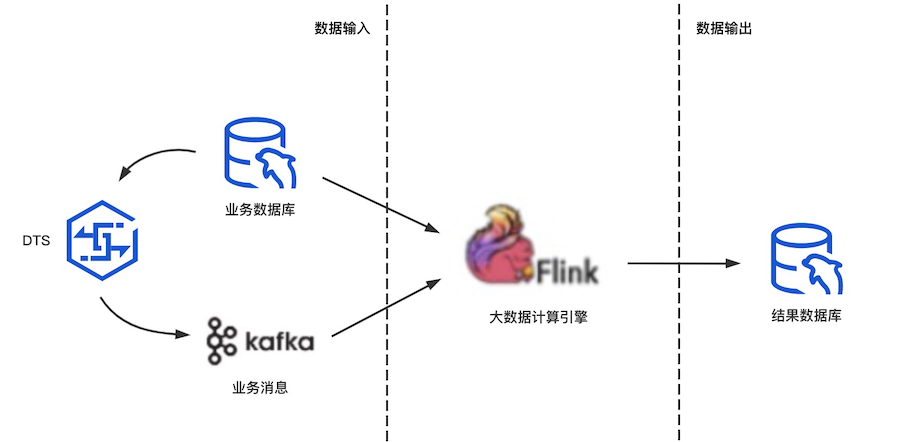
关键词
- 大数据计算
- SQL
痛点
解决计算海量数据计算量大、延迟高的性能问题,如用户画像需要计算大量业务和事件数据的场景。
商业价值
数据即价值
对平台积累的大量数据进行挖掘分析,创造出潜在的商业价值。
概述
什么是 Flink
Flink 是一个分布式计算引擎,可以用来做批处理,即处理历史数据;也可以用来做流处理,即实时地处理数据流,并实时地产生数据的结果。
Flink 特点:
- 性能突出:计算量大-百亿级、延迟低-秒级
- 支持 SQL 作业:只需要写 SQL 逻辑,简单上手快
- 有状态支持容错:即发生了失败,也不会丢失、多计算或者少计算
Flink 支持丰富的数据源,能满足大部分的业务场景需求。数据输入源支持 MySQL、Mongo 等数据库,也支持 Kafka 等事件消息中心;数据输出源支持 MySQL、Mongo、Redis 等数据库,也支持 Hbase、Hive 等数据仓库。
当前行业现状
Flink 已成为了大数据计算引擎的首选,国内各大厂都有相应的落地实践案例,技术比较成熟。各云厂商也都提供了相应的云计算产品:
解决方案介绍
Flink 怎样接入
Flink 数据输入端接入 MySQL 数据库和 Kafka 消息中心,能同时对业务数据和业务事件 2 种数据类型进行处理。
Flink 计算输出结果一般存储在 Hive、Hbase 等大数据数仓。 因此,接入已有系统数据源并不需要做任何改造。
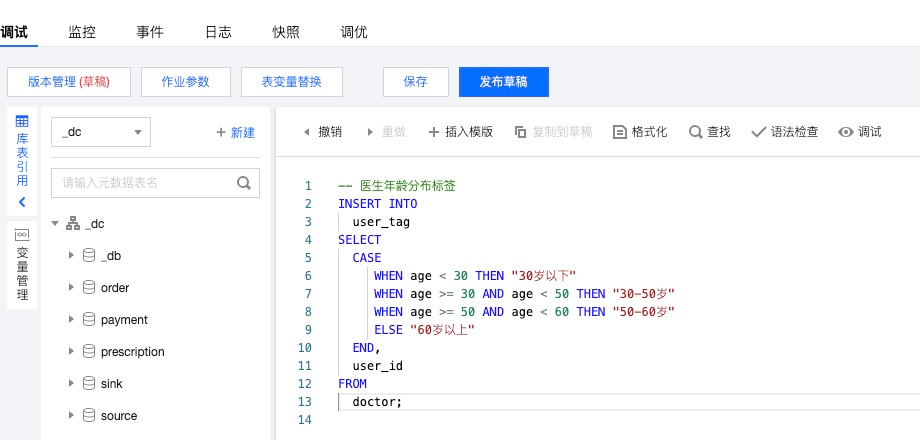
SQL 作业使用
数据的计算逻辑任务,一般都会选择 SQL 作业的类型。
对开发者友好,只需要用 SQL 表达出对应逻辑即可。
我们的机会
业务场景
用户画像
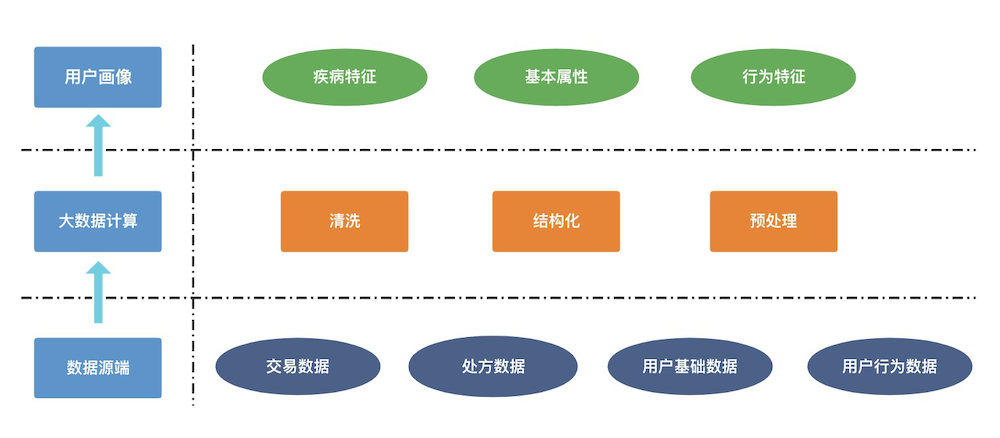
如图所示,交易数据、处方数据、用户基础数据、用户行为数据作为数据源,经过大数据 Flink 计算清洗、结构化、预处理后,产出疾病特征、基本属性、行为特征画像数据。
借助于 Flink,这一切只需要编写 SQL 即可,数据的处理、分布式调度我们都不需要关心。

