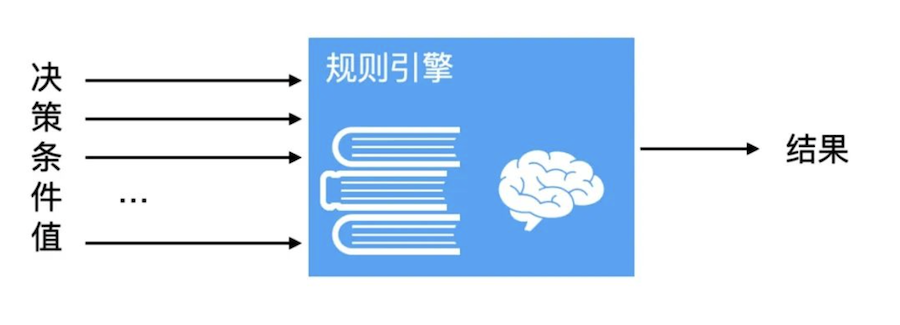
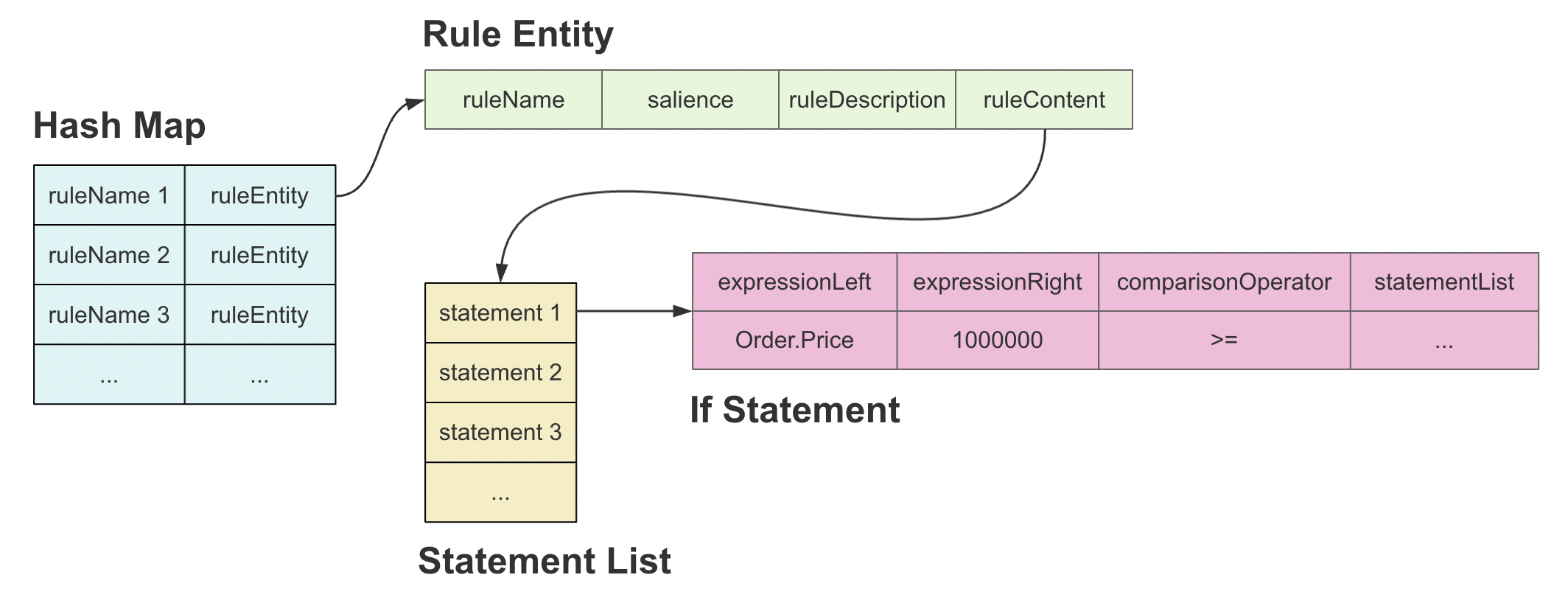
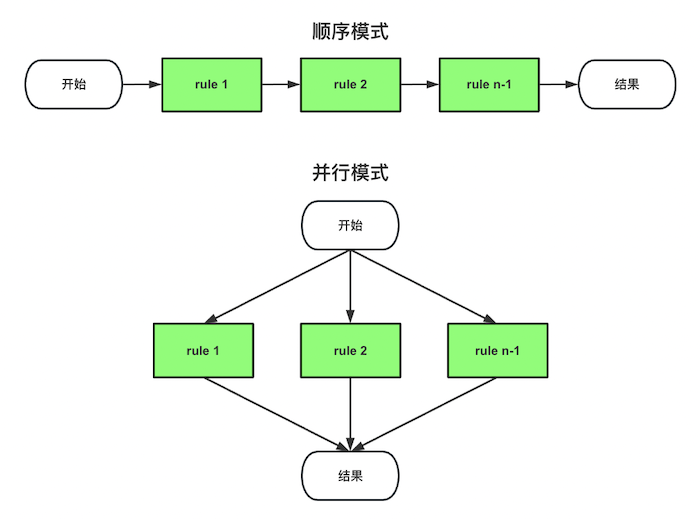
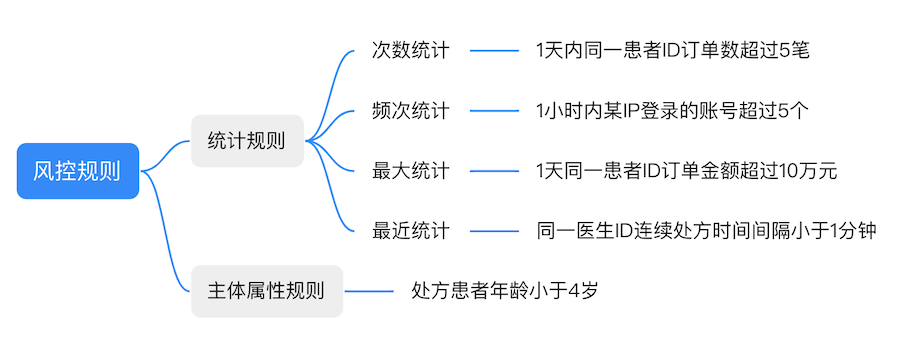
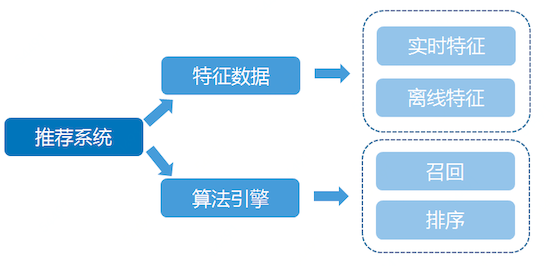
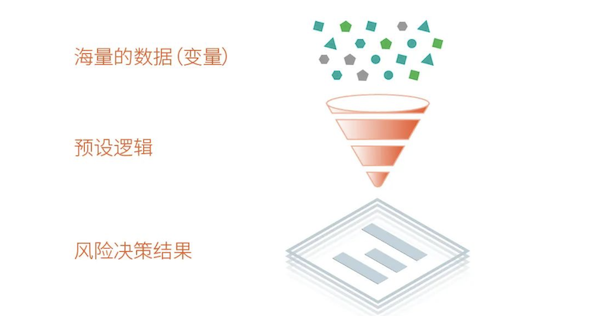
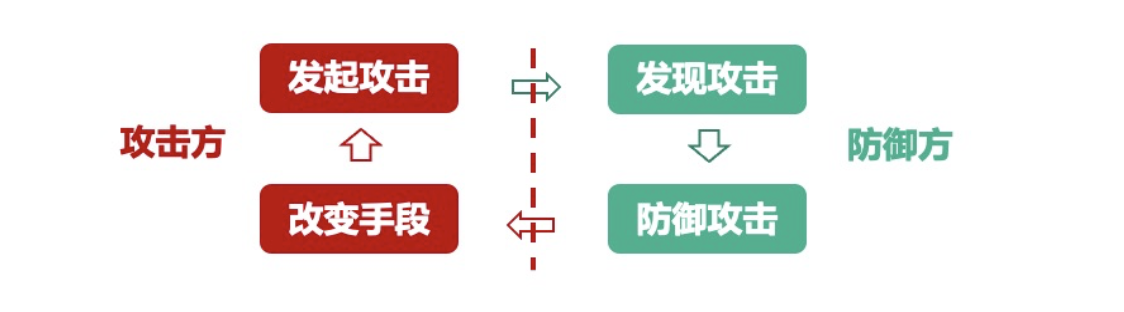
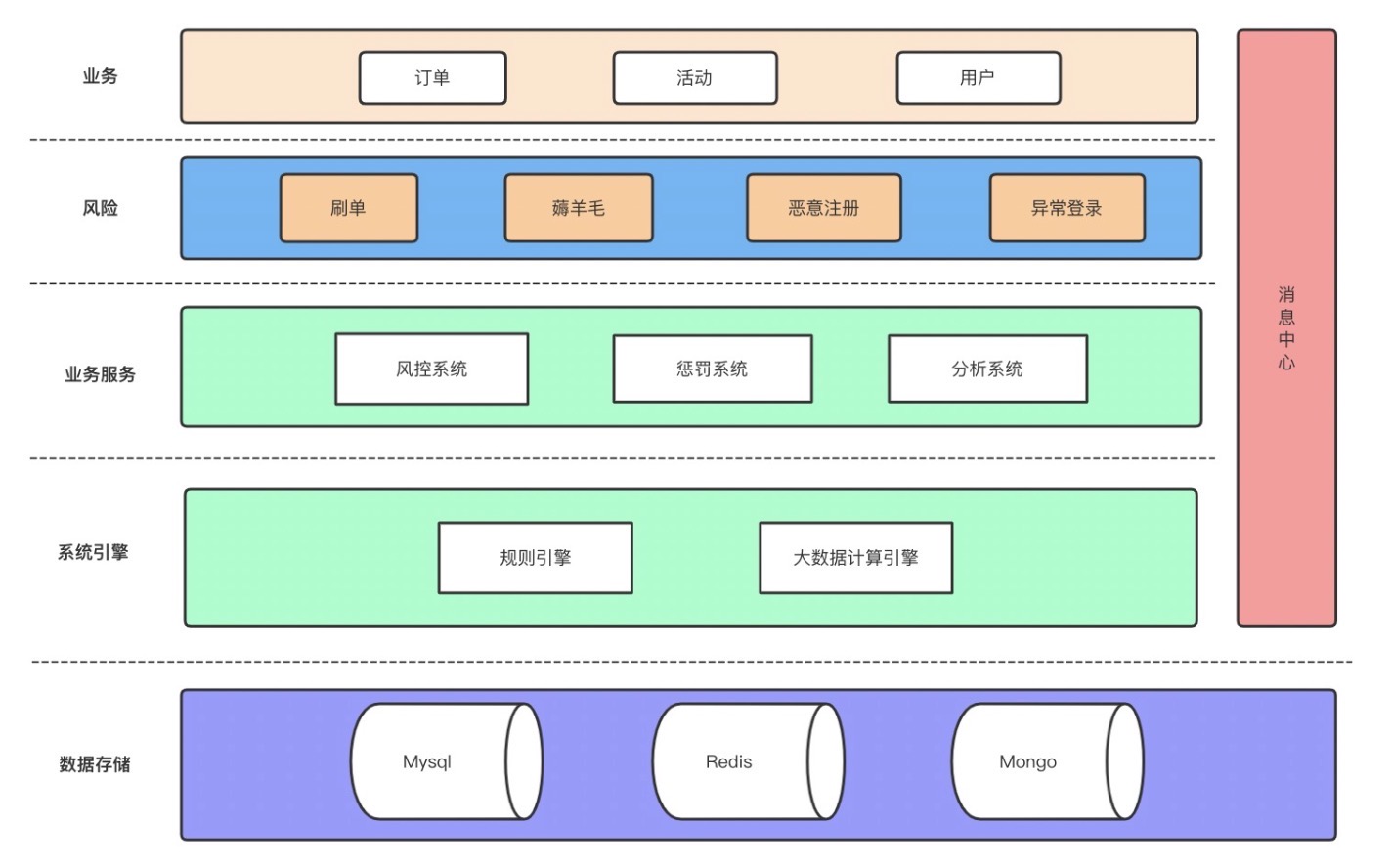
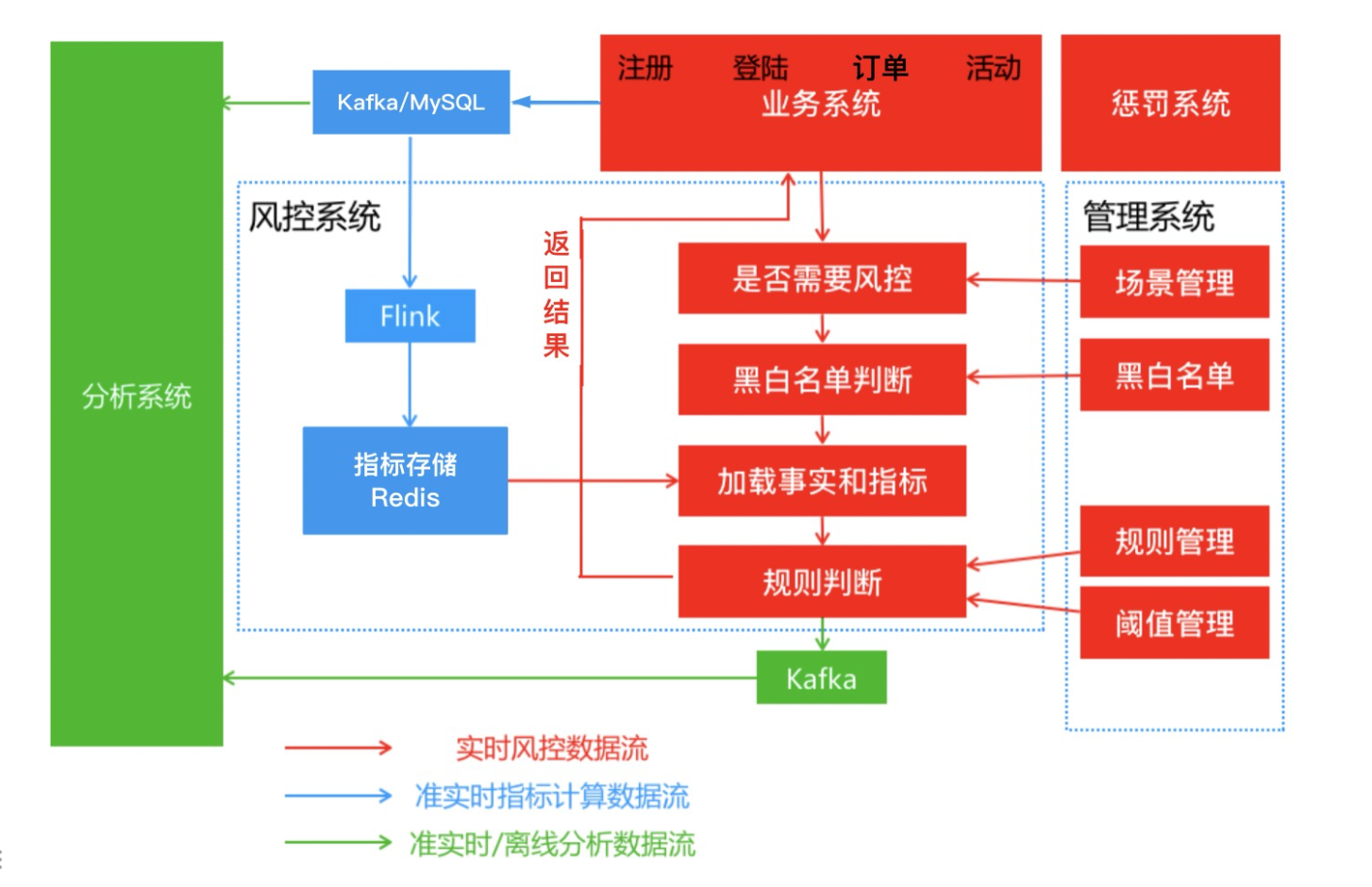
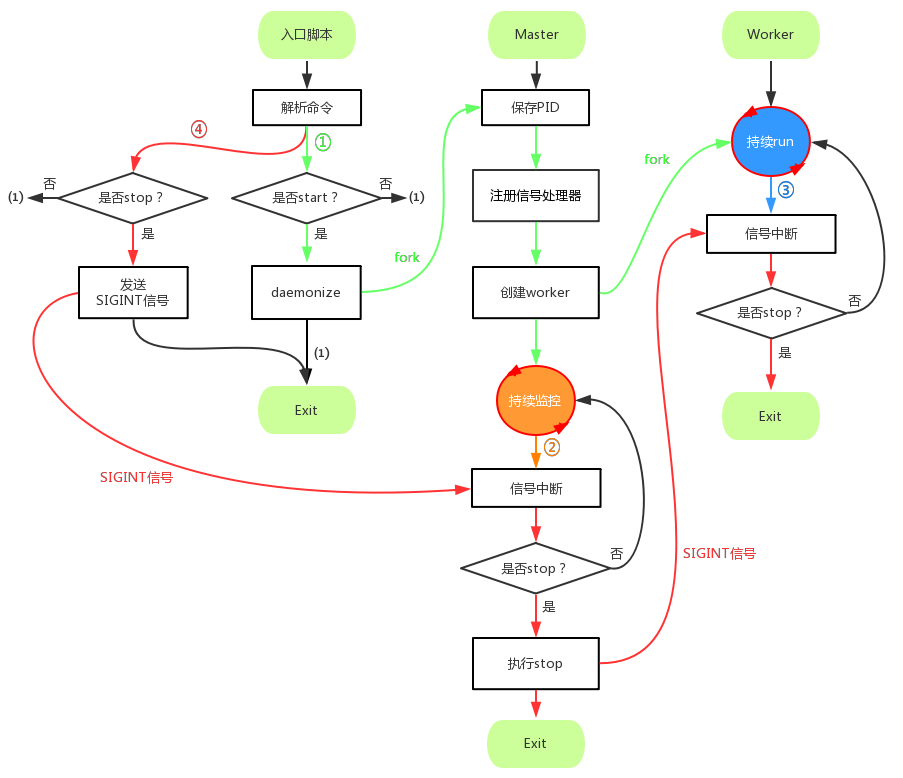
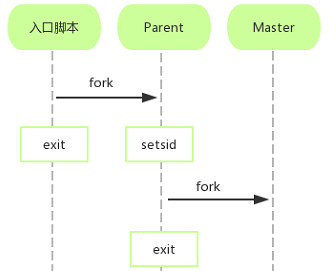
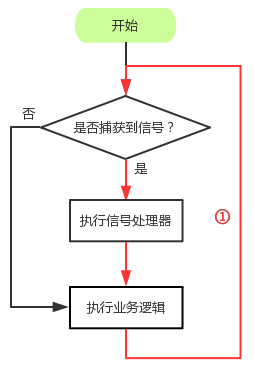
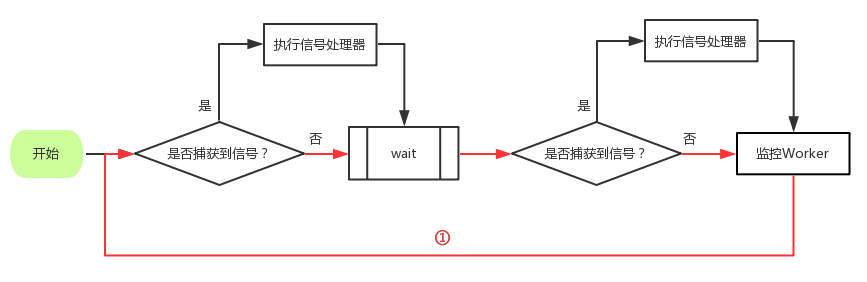
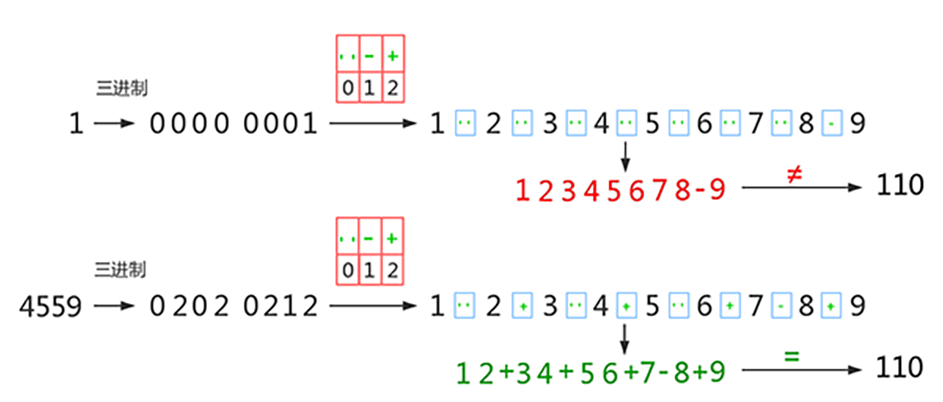
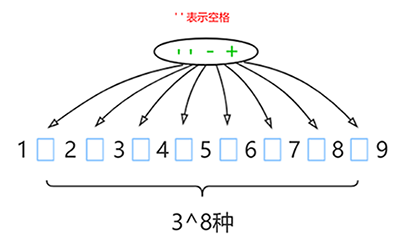
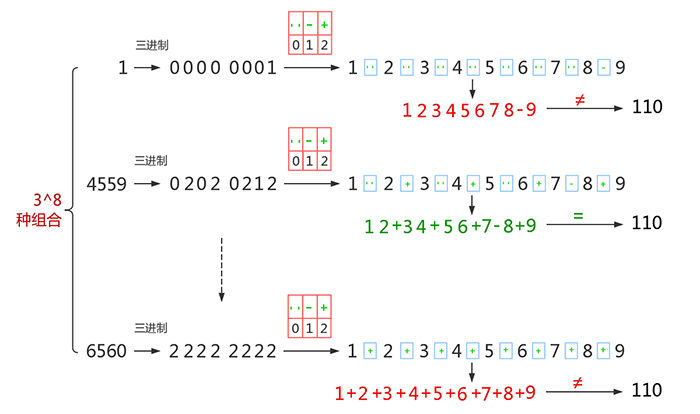
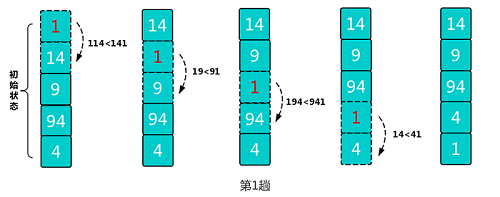
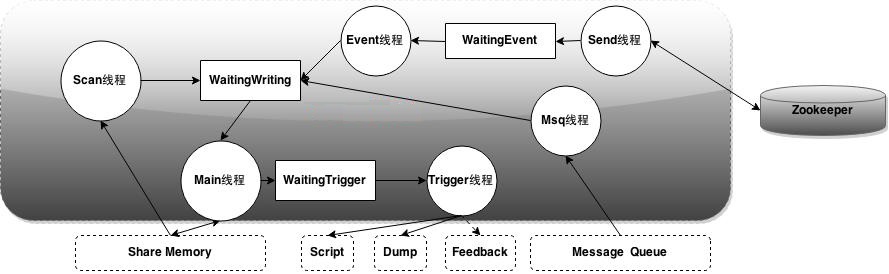
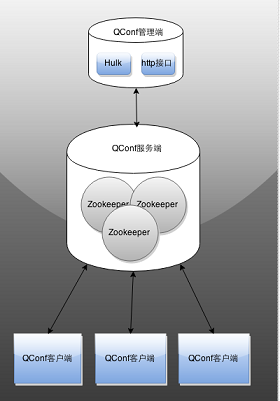
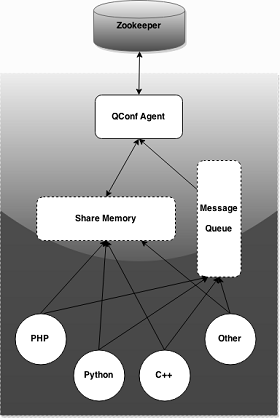
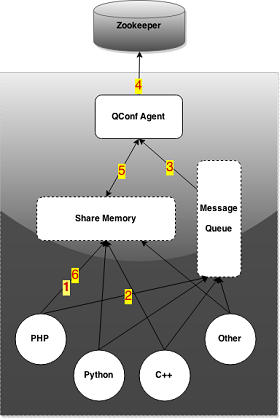
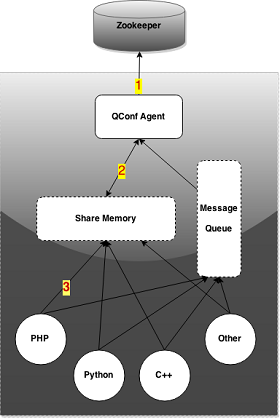
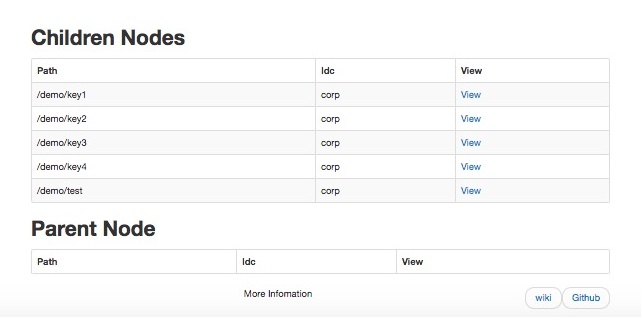
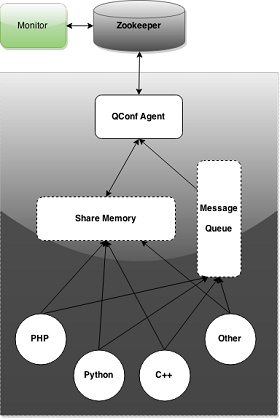
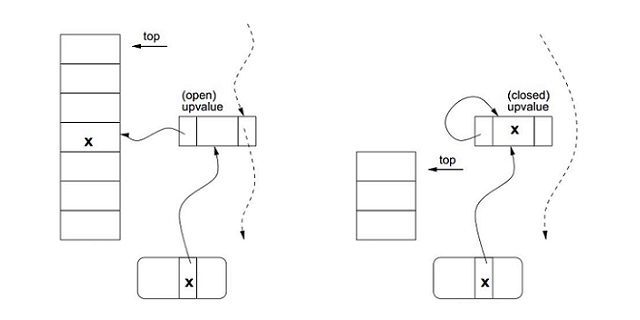
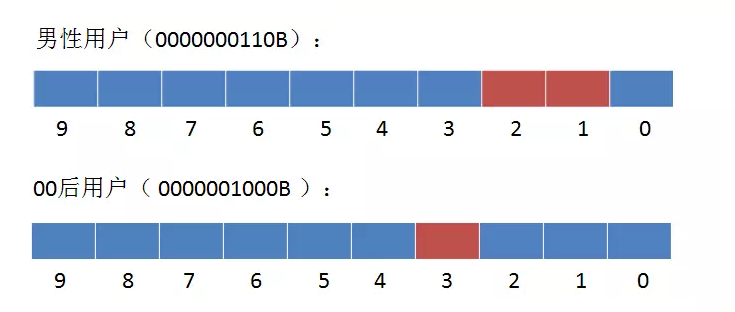
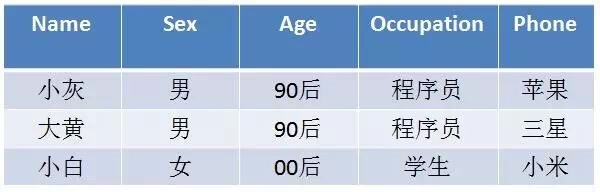
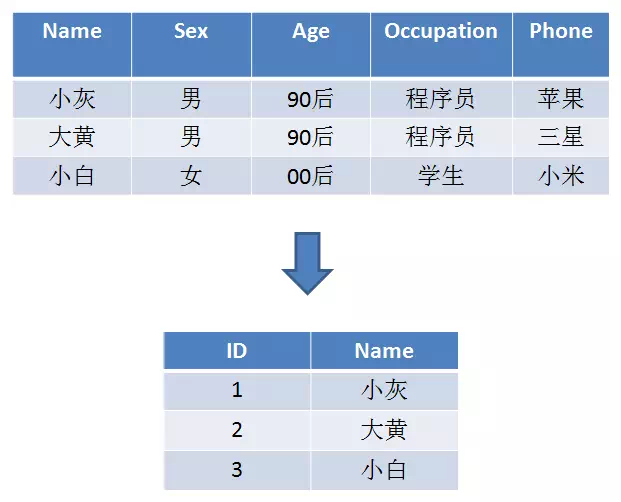
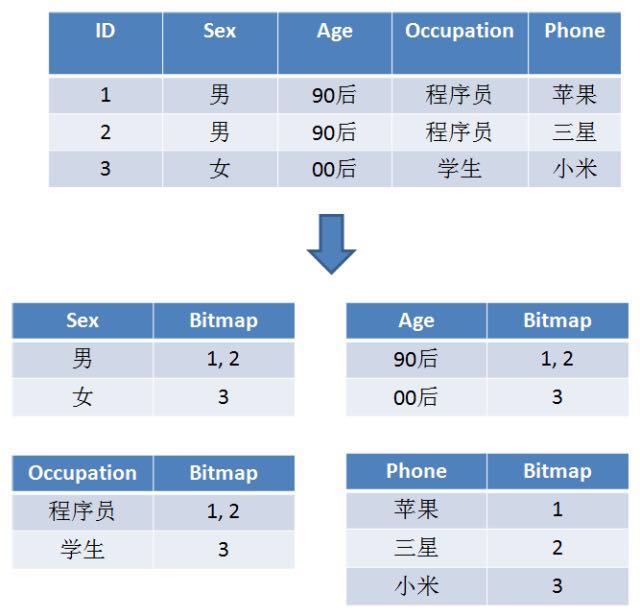
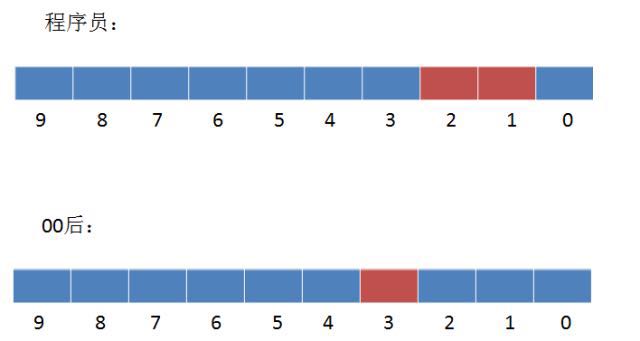
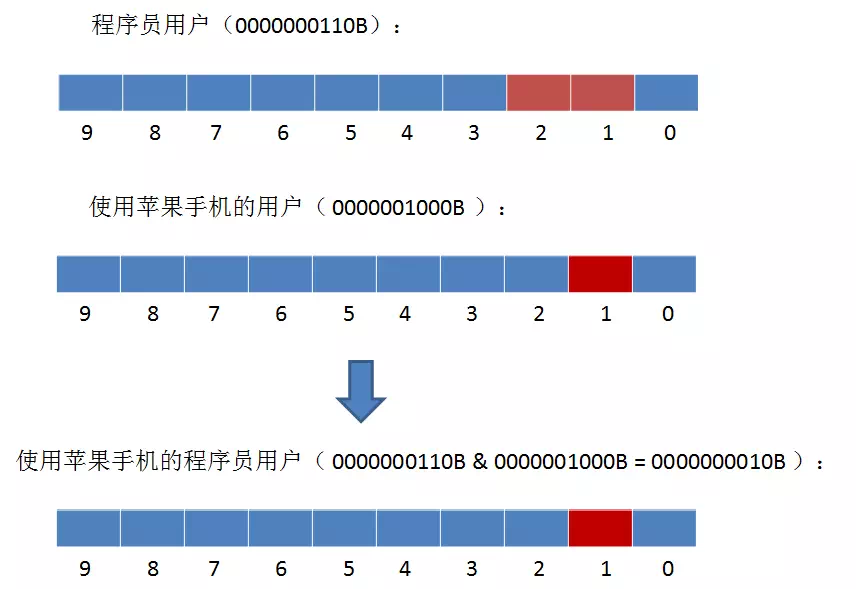
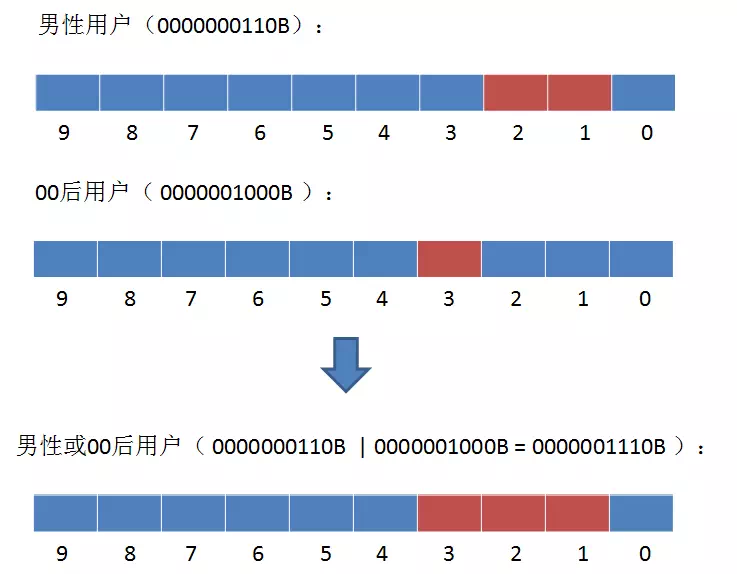
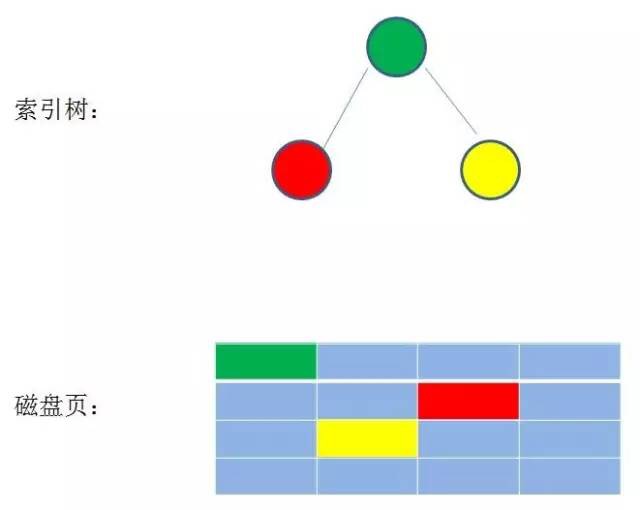
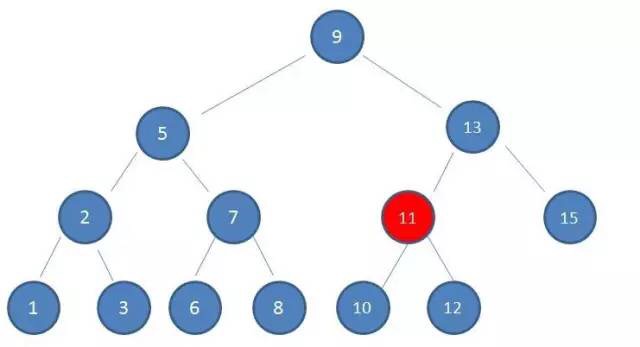
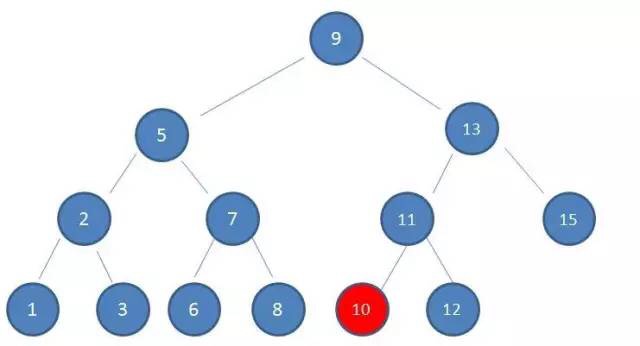
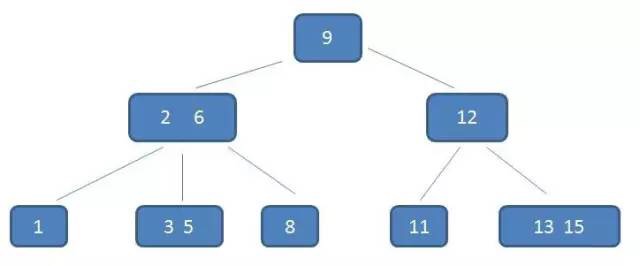
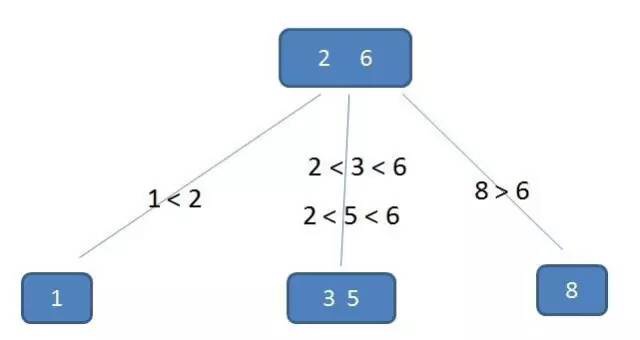
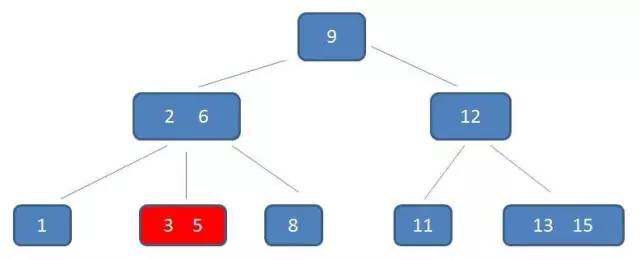
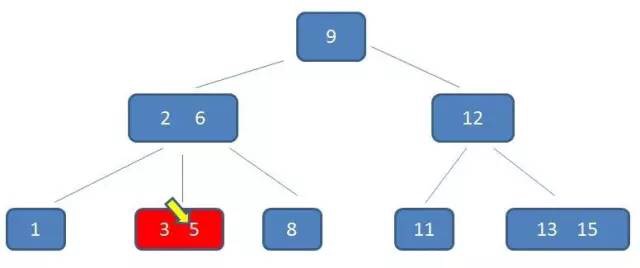
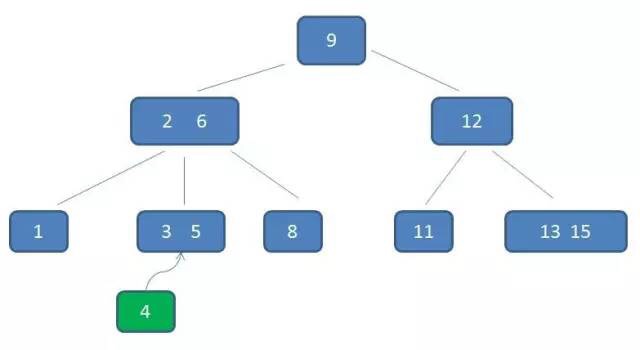
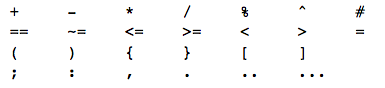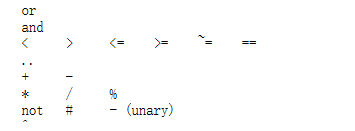type gengineListener interface { antlr.ParseTreeListener // 省略了一些只列举了部分方法 // EnterRuleEntity is called when entering the ruleEntity production. EnterRuleEntity(c *RuleEntityContext) // ExitRuleEntity is called when exiting the ruleEntity production. ExitRuleEntity(c *RuleEntityContext) // EnterRuleContent is called when entering the ruleContent production. EnterRuleContent(c *RuleContentContext) // ExitRuleContent is called when exiting the ruleContent production. ExitRuleContent(c *RuleContentContext) // EnterStatement is called when entering the statement production. EnterStatement(c *StatementContext) // ExitStatement is called when exiting the statement production. ExitStatement(c *StatementContext) // EnterIfStmt is called when entering the ifStmt production. EnterIfStmt(c *IfStmtContext) // ExitIfStmt is called when exiting the ifStmt production. ExitIfStmt(c *IfStmtContext) // EnterExpression is called when entering the expression production. EnterExpression(c *ExpressionContext) // ExitExpression is called when exiting the expression production. ExitExpression(c *ExpressionContext) // EnterInteger is called when entering the integer production. EnterInteger(c *IntegerContext) // ExitInteger is called when exiting the integer production. ExitInteger(c *IntegerContext) }
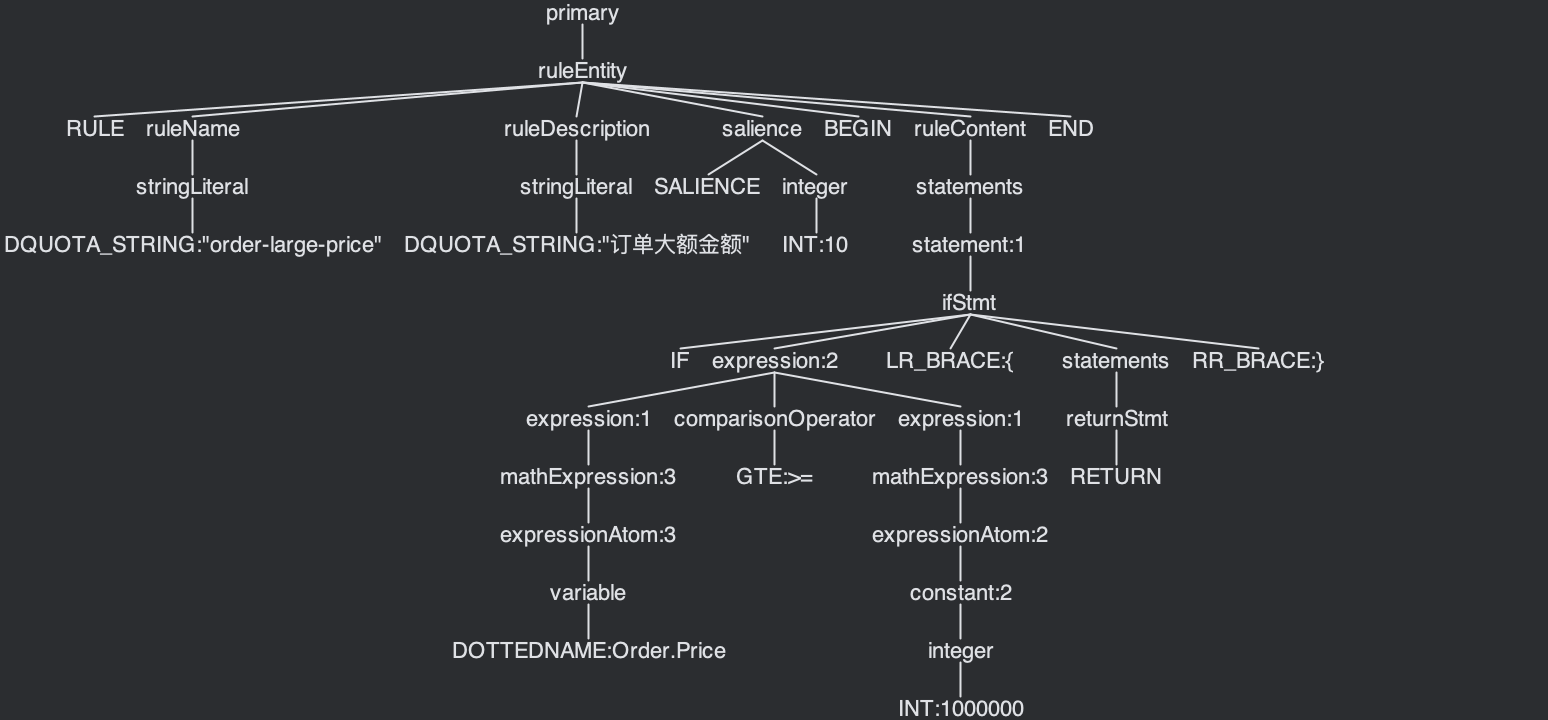
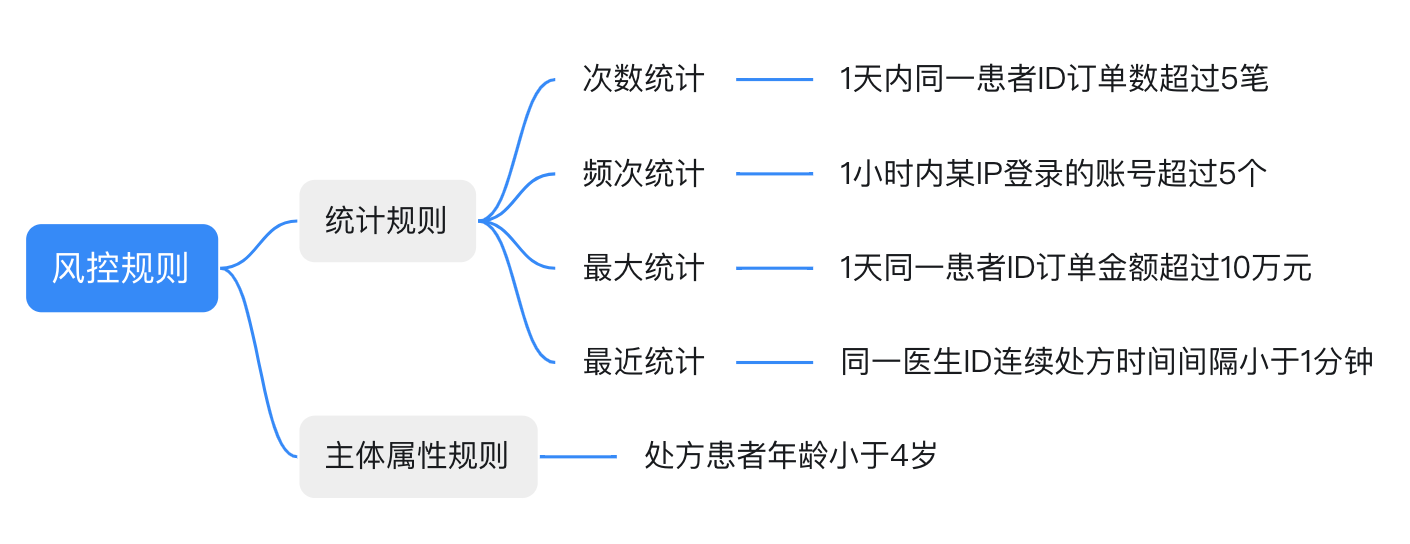
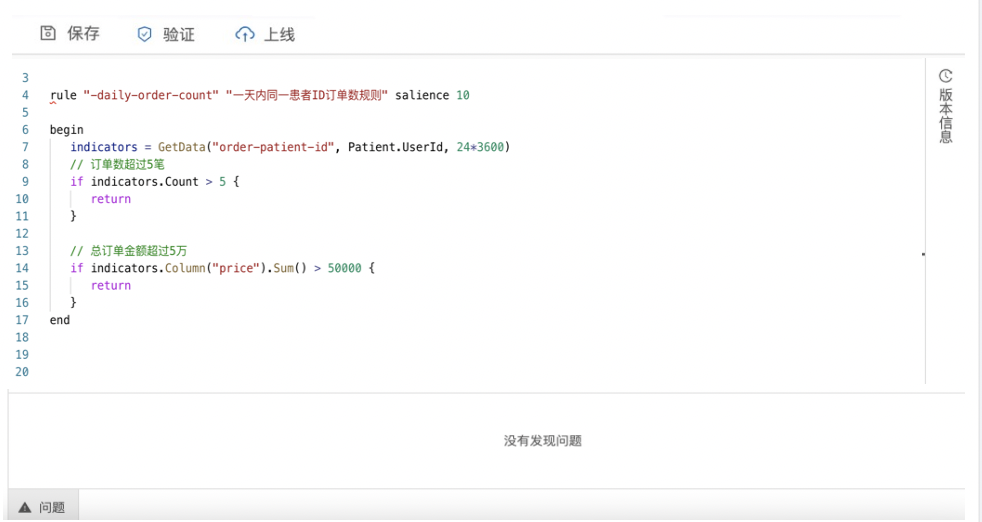
// 规则体 rule "test-func""测试自定义方法" salience 10 begin // 自定义方法GetCount获取指标数据(患者当天的订单数量) num = GetCount("order-patient-id", Order.PatientId) if num >= 5 { return } end
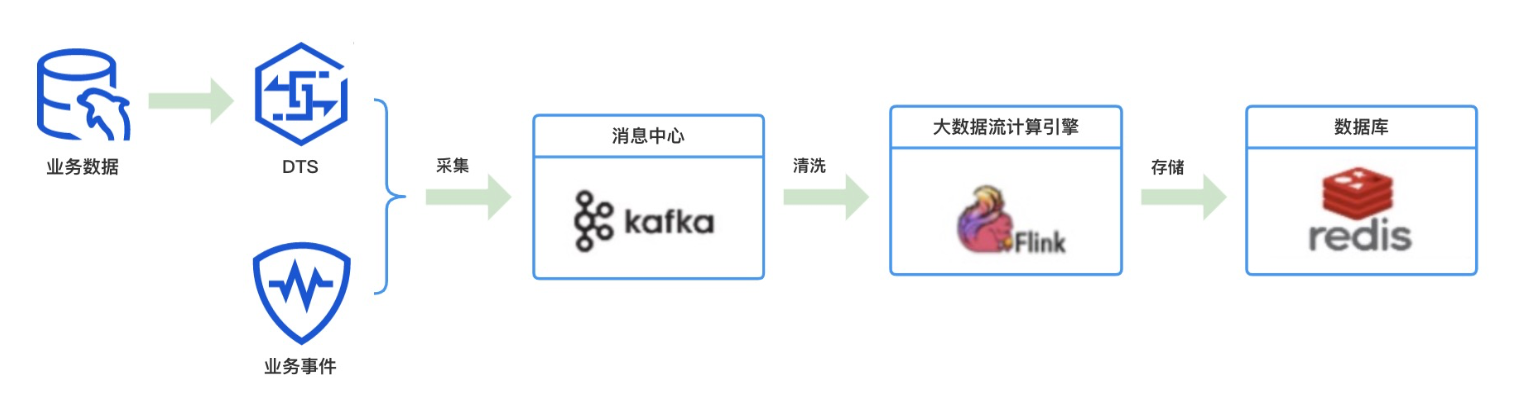
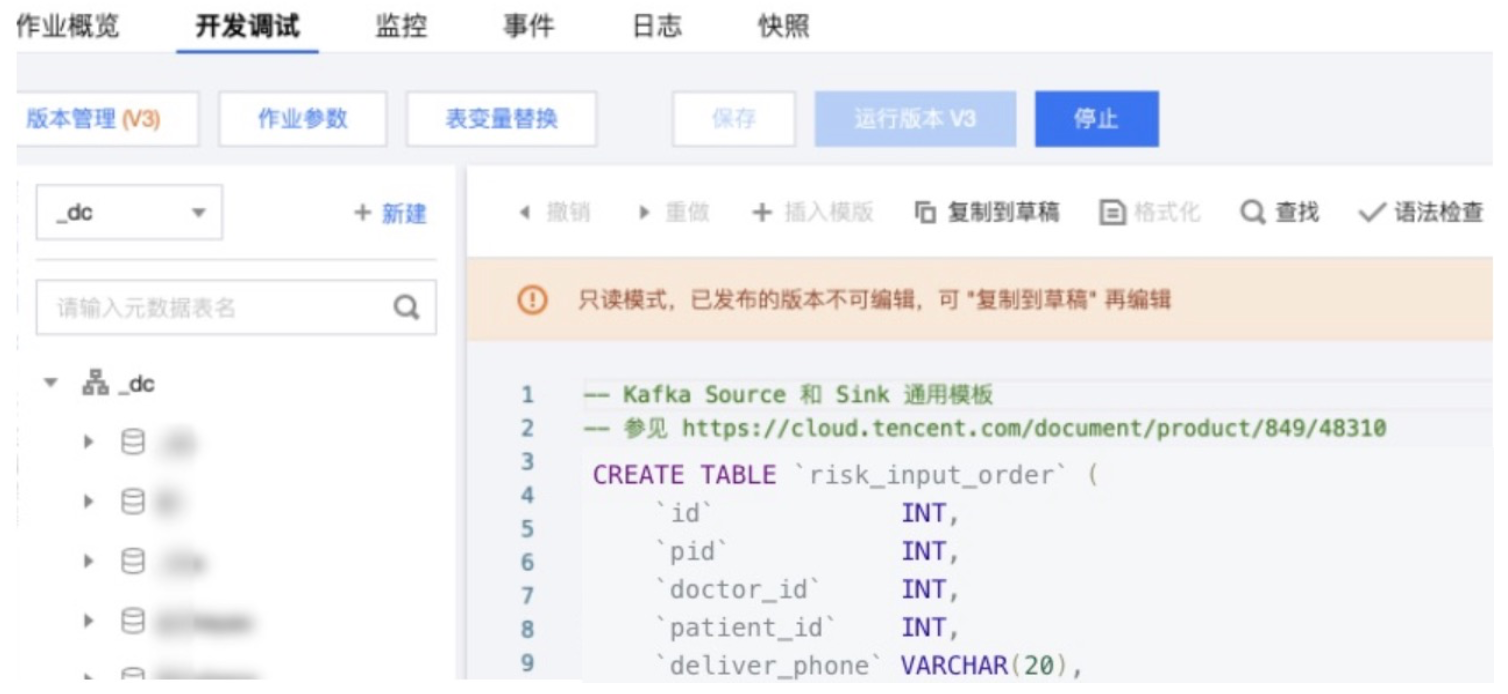
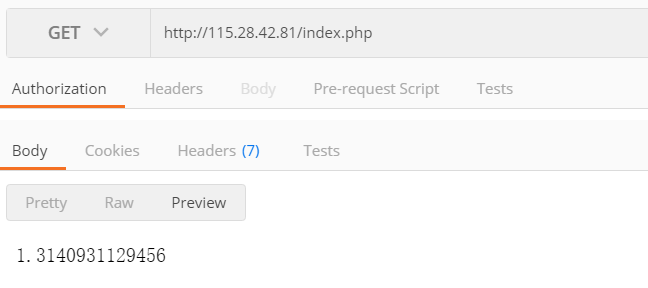
-- 清洗患者id维度订单数据 INSERTINTO risk_output_order_patient_id SELECT CONCAT('risk:order-patient-id:', patient_id) AS `key`, id ASvalue, UNIX_TIMESTAMP(created_at) AS score FROM risk_input_order WHERE pid =0;
docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES b0307bac08d7 blog_nodejs "sh /start.sh" 2 days ago Up 2 days 0.0.0.0:4000->4000/tcp nodejs e8ef7a1e9271 blog_nginx "/docker-entrypoint.…" 2 days ago Up 2 days 0.0.0.0:80->80/tcp nginx af7baad788c5 blog_php "docker-php-entrypoi…" 2 days ago Up 2 days 9000/tcp php
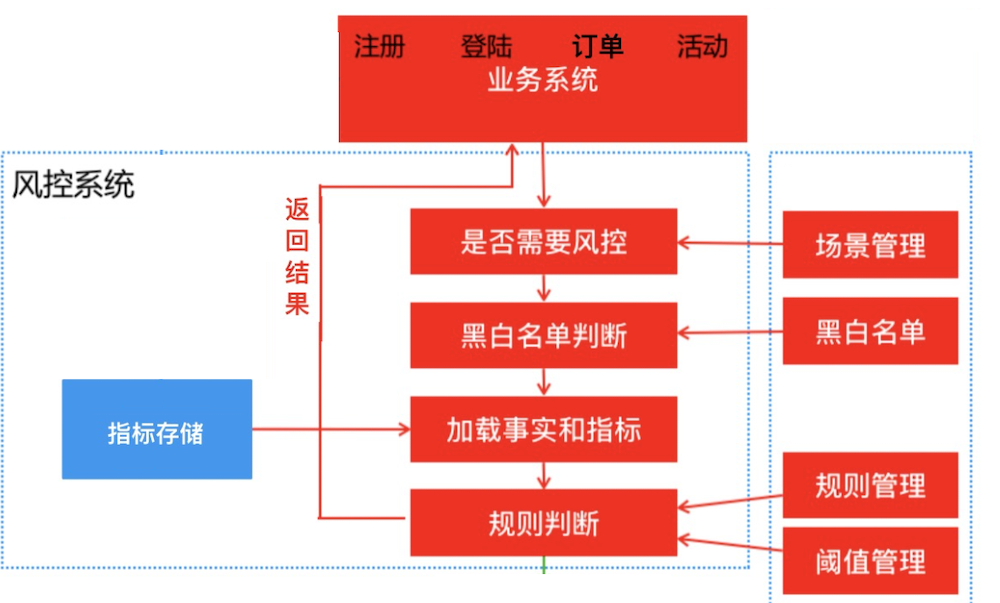
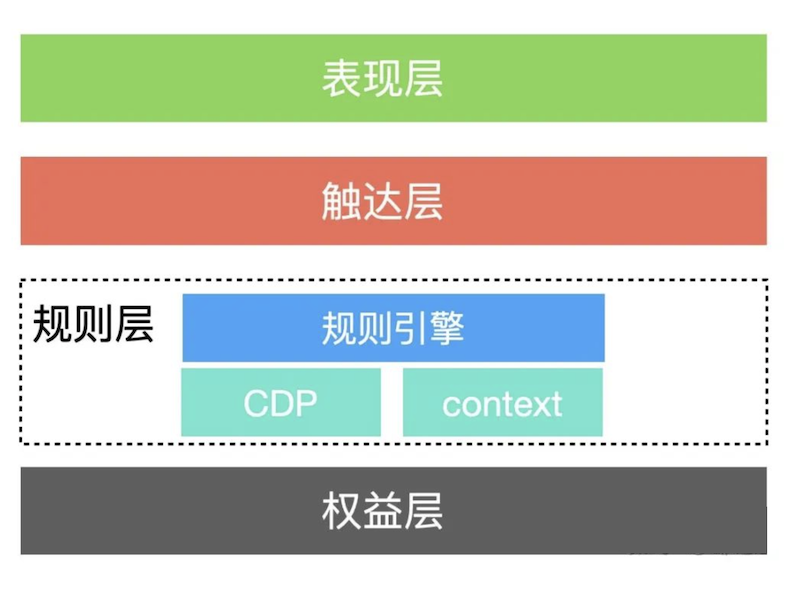
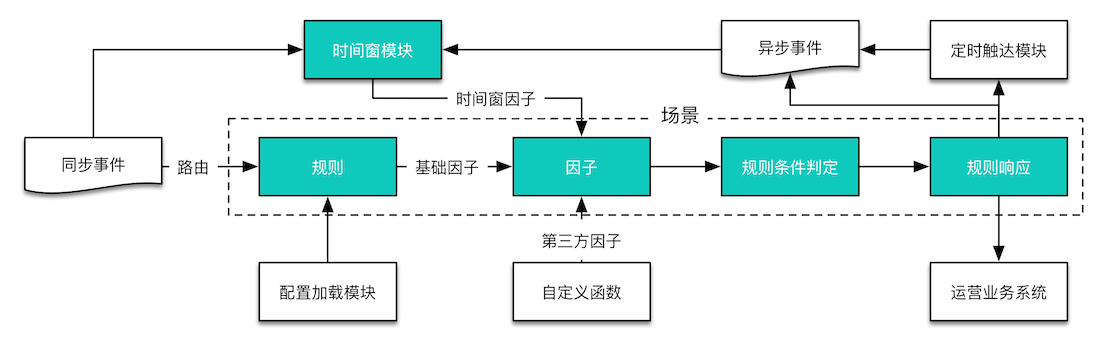
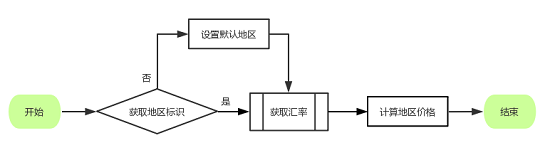
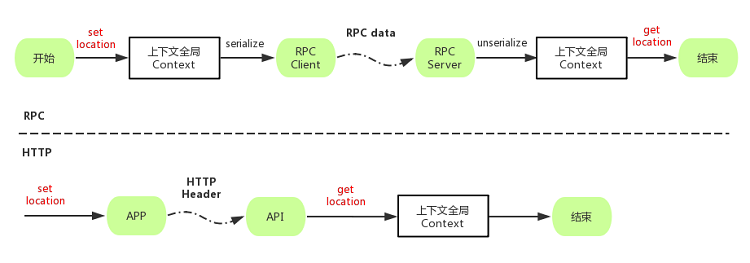
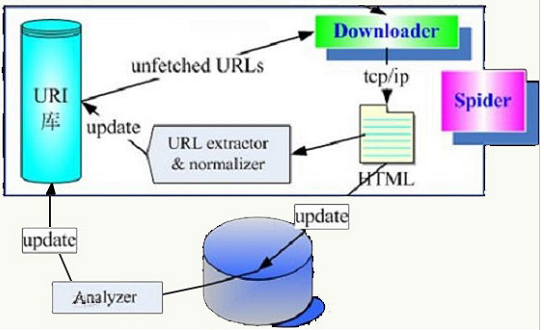
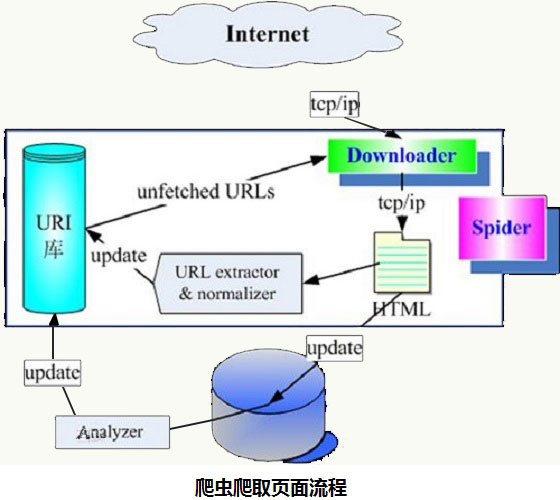
我们的业务系统主要分为 API 和 Service 项目,API 暴露出 HTTP 接口,API 与 Service 和 Service 与 Service 之前使用 RPC 接口通信。由于商品中心涉及到价格的接口繁多,不可能对每个接口都增加地区标识的参数。所以我们弄了一套调用链路透传地区标识的机制。
protectedstaticfunctionsignalHandler($signal) { switch($signal) { case SIGINT: case SIGTERM: static::stop(); break; case SIGQUIT: case SIGUSR1: static::reload(); break; default: break; } }
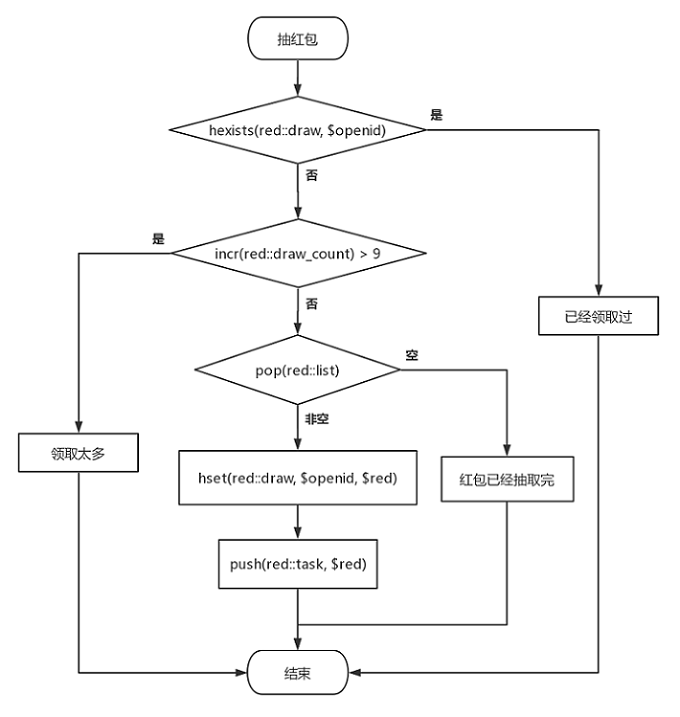
-- 领取人的openid为xxxxxxxxxxx local openid = 'xxxxxxxxxxx' local isDraw = redis.call('HEXISTS', 'red::draw', openid) -- 已经领取 if isDraw ~= 0then returntrue end -- 领取太多次了 local times = redis.call('INCR', 'red::draw_count:u:'..openid) if times andtonumber(times) > 9then return0 end
local number = redis.call('RPOP', 'red::list') -- 没有红包 ifnot number then return {} end -- 领取人昵称为Fhb,头像为https://xxxxxxx local red = {money=number,name='Fhb',pic='https://xxxxxxx'} -- 领取记录 redis.call('HSET', 'red::draw', openid, cjson.encode(red)) -- 处理队列 red['openid'] = openid redis.call('RPUSH', 'red::task', cjson.encode(red))
for index in${indices}; do date=`echo$index | sed "s/.*\([0-9]\{4\}\([.\-][0-9]\{2\}\)*\).*/\1/g" | sed 's/[.\-]/-/g'` if [ `echo$date | grep -o \- | wc -l` = 1 ]; thendate="$date-01"; fi
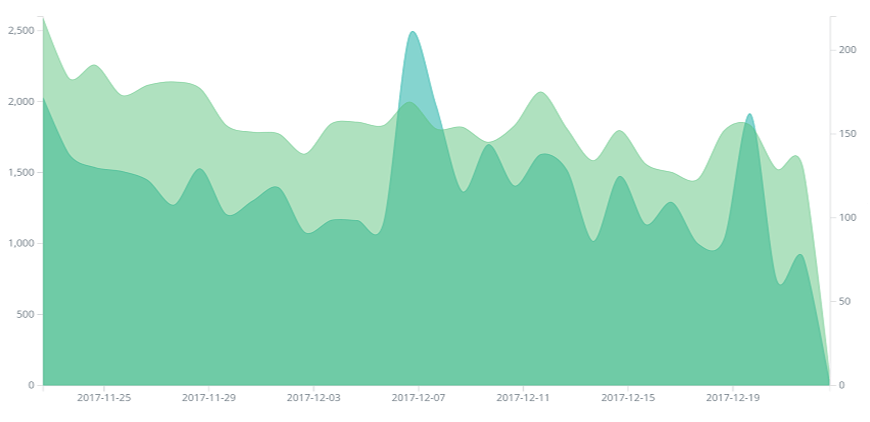
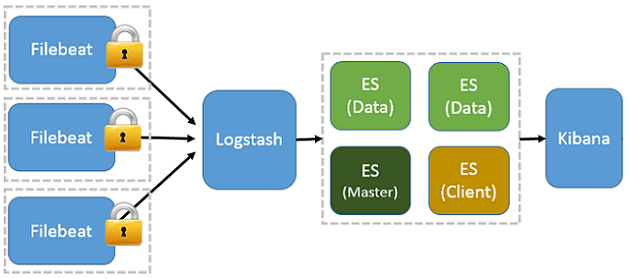
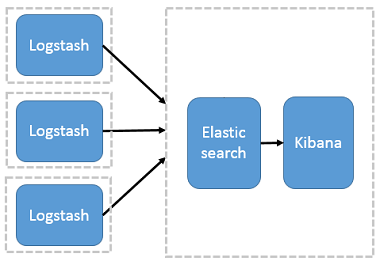
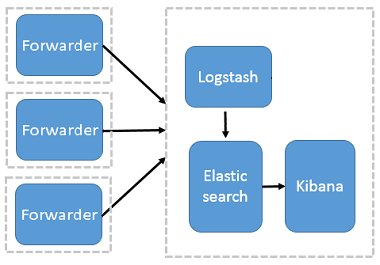
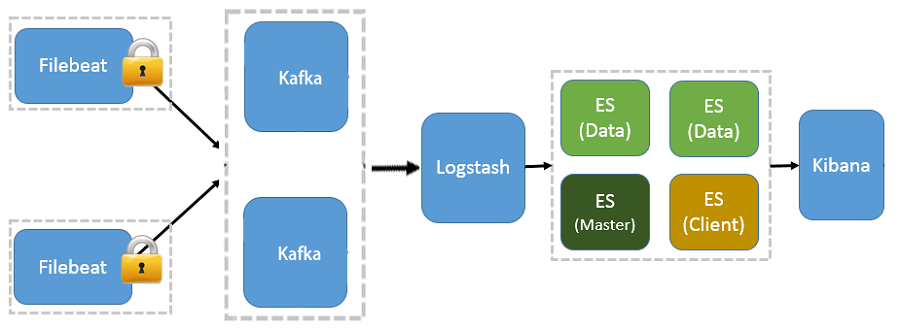
$ service filebeat start # 查看推送日志 $ tailf /usr/local/elk/beats/filebeat/bin/logs/filebeat 2017-12-22T02:00:53+08:00 INFO Non-zero metrics in the last 30s: filebeat.harvester.open_files=1 filebeat.harvester.running=1 libbeat.logstash.publish.read_bytes=6 libbeat.logstash.publish.write_bytes=460
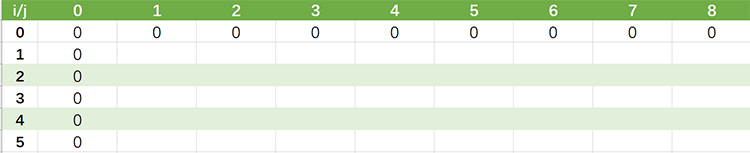
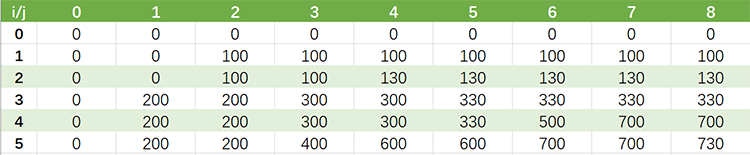
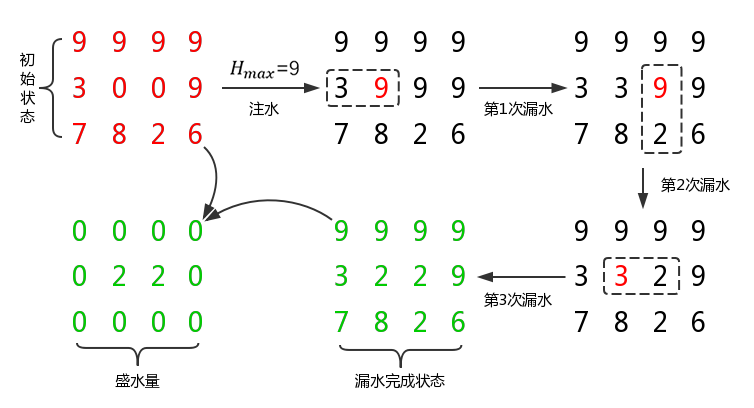
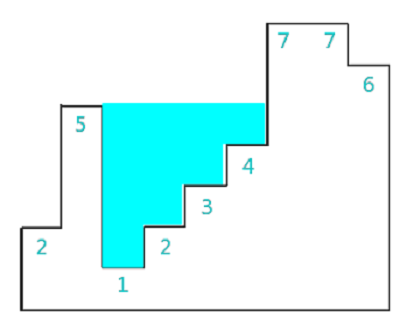
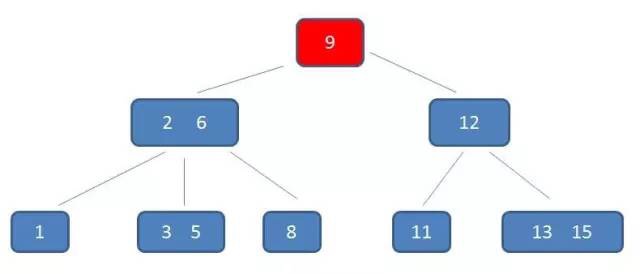
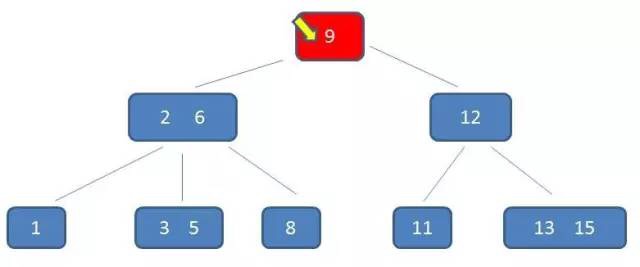
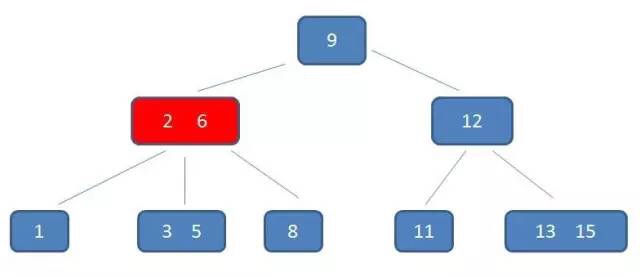
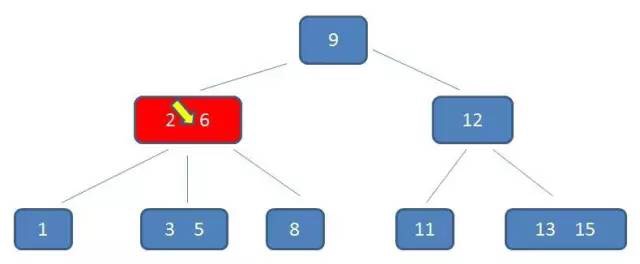
假设,师傅挣取价值最大时的订单为 $x_1$,$x_2$,$x_3$,…,$x_i$(其中 $x_i$ 取 1 或 0,表示第 i 个订单被安排或者不安排),$v_i$ 表示第 i 个订单的价值,$w_i$ 表示第 i 个订单的耗时时长,$wv(i,j)$ 表示安排了第 i 个订单,师傅总耗时为 j 时的最大价值。
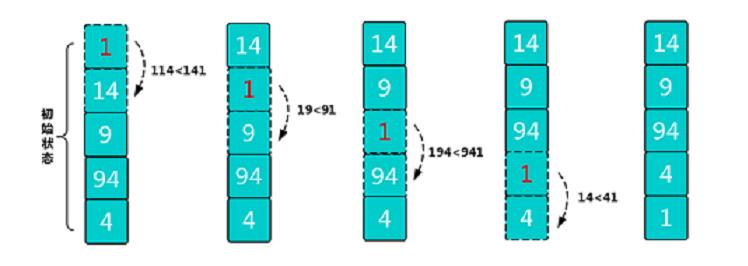
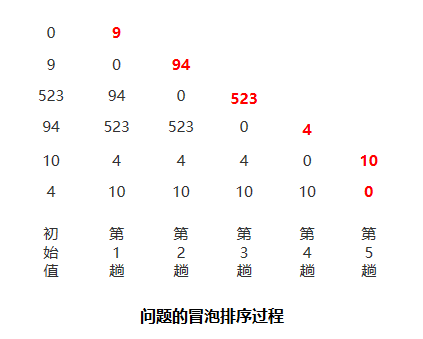
比较规则:分析 a 和 b 的排列,因为这 2 个数存在 2 种排列情况,既 a_b 和 b_a,若 a_b 组合值大于 b_a 组合,那么认为 a “大于” b,则 a 需要排列在 b 前面,反之则需要交换 a 和 b 的位置。同我们熟悉的排序算法唯一不同的是,这里不是直接通过比较 2 个元素值大小,而是需要通过排列后的 2 个新值进行大小比较。
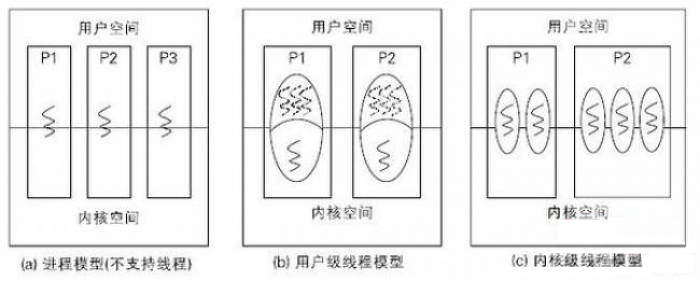
许多协同式多任务操作系统,也可以看成协程运行系统。说到协同式多任务系统,一个常见的误区是认为协同式调度比抢占式调度“低级”,因为我们所熟悉的桌面操作系统,都是从协同式调度(如 Windows 3.2, Mac OS 9 等)过渡到抢占式多任务系统的。实际上,调度方式并无高下,完全取决于应用场景。抢占式系统允许操作系统剥夺进程执行权限,抢占控制流,因而天然适合服务器和图形操作系统,因为调度器可以优先保证对用户交互和网络事件的快速响应。当年 Windows 95 刚刚推出的时候,抢占式多任务就被作为一大买点大加宣传。协同式调度则等到进程时间片用完或系统调用时转移执行权限,因此适合实时或分时等等对运行时间有保障的系统。
另外,抢占式系统依赖于 CPU 的硬件支持。 因为调度器需要“剥夺”进程的执行权,就意味着调度器需要运行在比普通进程高的权限上,否则任何“流氓(rogue)”进程都可以去剥夺其他进程了。只有 CPU 支持了执行权限后,抢占式调度才成为可能。x86 系统从 80386 处理器开始引入 Ring 机制支持执行权限,这也是为何 Windows 95 和 Linux 其实只能运行在 80386 之后的 x86 处理器上的原因。而协同式多任务适用于那些没有处理器权限支持的场景,这些场景包含资源受限的嵌入式系统和实时系统。在这些系统中,程序均以协程的方式运行。调度器负责控制流的让出和恢复。通过协程的模型,无需硬件支持,我们就可以在一个“简陋”的处理器上实现一个多任务的系统。我们见到的许多智能设备,如运动手环,基于硬件限制,都是采用协同调度的架构。
从编程角度上看,协程的思想本质上就是控制流的主动让出(yield)和恢复(resume)机制,迭代器常被用来实现协程,所以大部分的语言实现的协程中都有 yield 关键字,比如 Python、PHP、Lua。但也有特殊比如 Go 就使用的是通道来通信。
有趣的是协程的历史其实要早于线程。
WIKI 的解释:
Coroutines are computer program components that generalize subroutines for non-preemptive multitasking, by allowing multiple entry points for suspending and resuming execution at certain locations. Coroutines are well-suited for implementing more familiar program components such as cooperative tasks, exceptions, event loop, iterators, infinite lists and pipes.
co2 = coroutine.create( function() for i=1,10do print(i) if i == 3then print(coroutine.status(co2)) print(coroutine.running()) -- 返回正在跑的coroutine end coroutine.yield() -- 挂起coroutine end end )
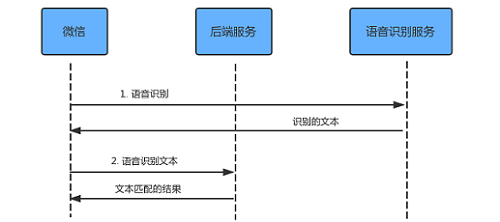
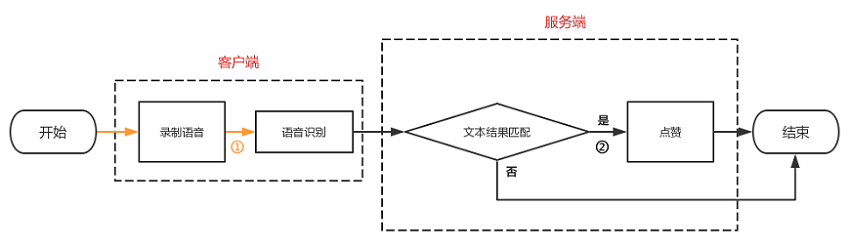
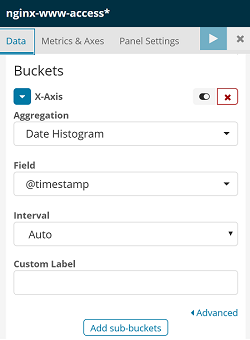
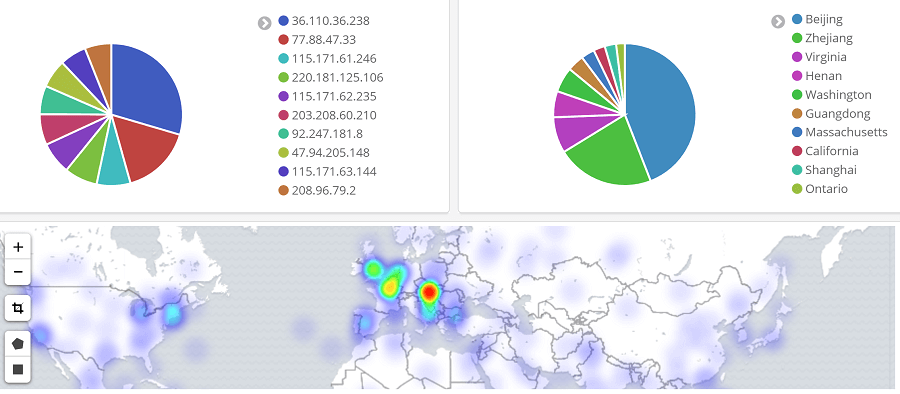
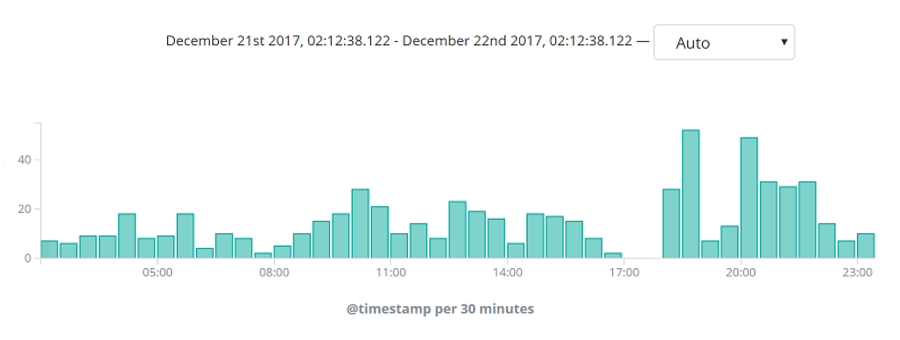
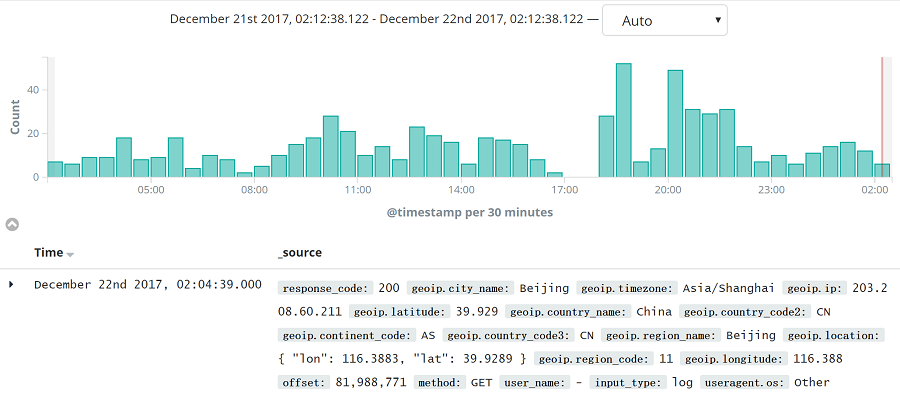
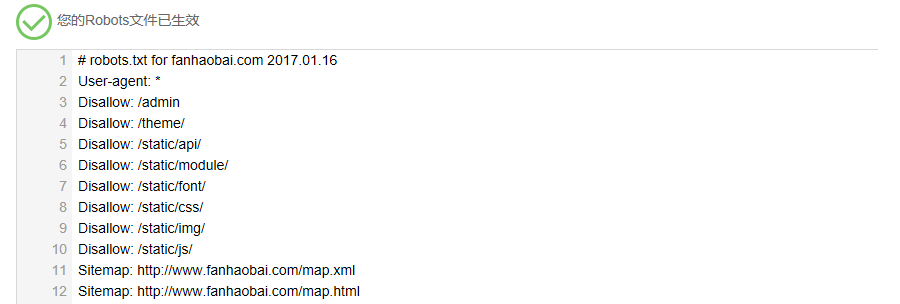
使用 Lua 模块对本站的 ES 服务做受信操作控制,即非受信 IP 只能查询操作。nginx.conf配置如下:
location / { set $allowed '115.171.226.212'; access_by_lua_block { if ngx.re.match(ngx.req.get_method(), "PUT|POST|DELETE") andnot ngx.re.match(ngx.var.request_uri, "_search") then start, _ = string.find(ngx.var.allowed, ngx.var.remote_addr) ifnot start then ngx.exit(403) end end }
local redis = require"resty.redis" local red = redis:new()
local limit = tonumber(ngx.var.rate_per) or200 local expire_time = tonumber(ngx.var.rate_expire) or1000 local key = "rate.limit:string:"
red:set_timeout(500) local ok, err = red:connect("www.fanhaobai.com", 6379) ifnot ok then ngx.log(ngx.ERR, "failed to connect redis: " .. err) return end
key = key .. ngx.md5(ngx.var.request_uri .. (ngx.req.get_uri_args()['token'] or ngx.req.get_post_args()['token'])) local times, err = red:incr(key) ifnot times then ngx.log(ngx.ERR, "failed to exec incr: " .. err) return elseif times == 1then ok, err = red:expire(key, expire_time) ifnot ok then ngx.log(ngx.ERR, "failed to exec expire: " .. err) return end end
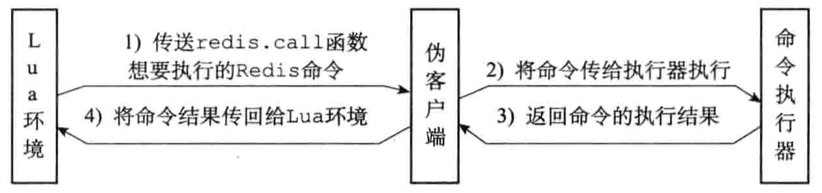
> EVAL "redis.log(redis.LOG_NOTICE, 'I am fhb')"0 113:M 04 Sep 13:12:36.229 * I am fhb
案例
API 访问速率控制
通过 Lua 实现一个针对用户的 API 访问速率控制,Lua 代码如下:
local key = "rate.limit:string:" .. KEYS[1] local limit = tonumber(ARGV[1]) local expire_time = tonumber(ARGV[2]) local times = redis.call("INCR", key) if times == 1then redis.call("EXPIRE", key, expire_time) end if times > limit then return0 end return1
KEYS[1] 可以用 API 的 URI + 用户 uid 组成,ARGV[1] 为单位时间限制访问的次数,ARGV[2] 为限制的单位时间。
-- KEYS为uid数组 local users = {} for i,uid inipairs(KEYS) do local user = redis.call('hgetall', uid) if user ~= nilthen table.insert(users, i, user) end end return users
取反操作 not 总是返回 false 或 true 中的一个。 and 和 or 都遵循短路规则,也就是说 and 操作符在第一个操作数为 false 或 nil 时,返回这第一个操作数, 否则,and 返回第二个参数; or 操作符在第一个操作数不为 nil 和 false 时,返回这第一个操作数,否则返回第二个操作数。
10and20--> 20 niland10--> nil 10or20--> 10 nilor"a"--> "a" notfalse--> true
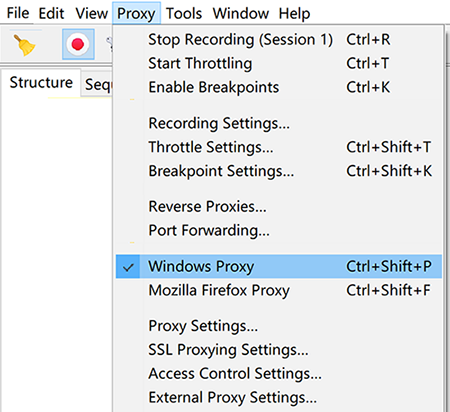
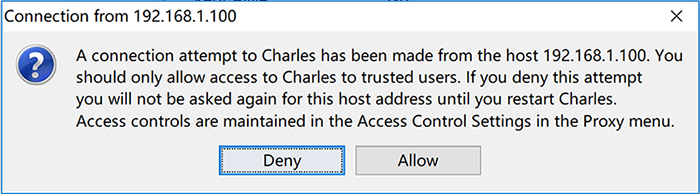
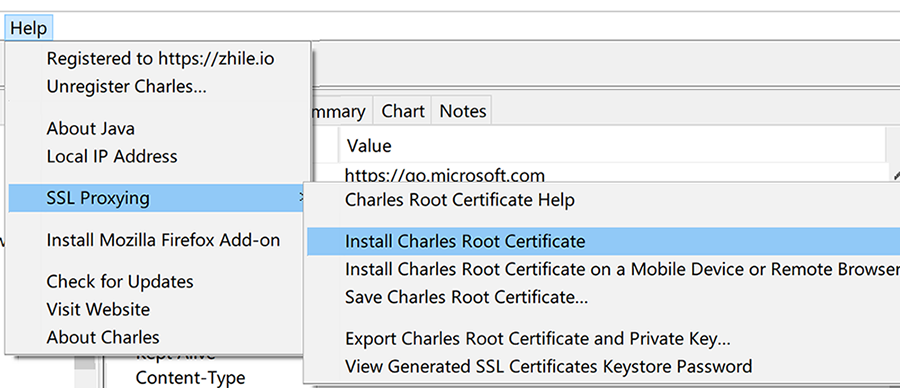
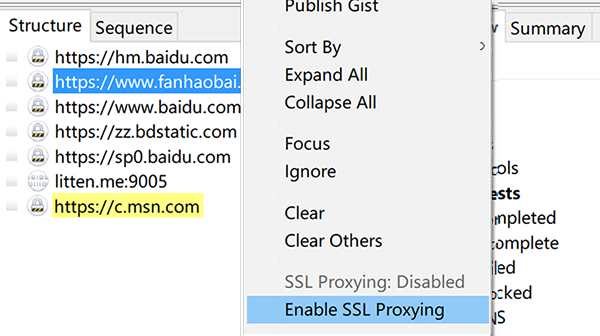
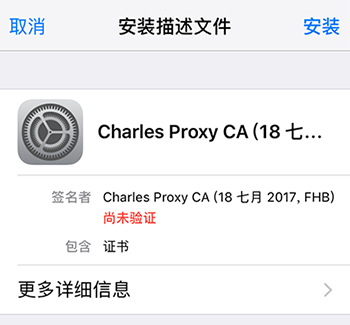
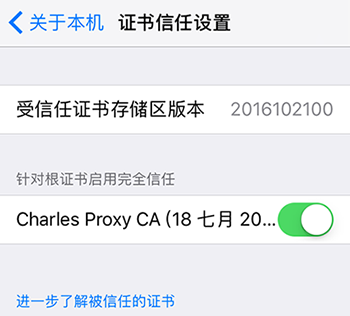
如果在 iPhone 或 Android 机器上截取 Https 协议的通讯内容,需要手机上安装相应的证书。点击 Charles 的顶部菜单,选择 “Help” -> “SSL Proxying” -> “Install Charles Root Certificate on a Mobile Device or Remote Browser”,然后按照 Charles 的提示的安装教程安装即可。如下图所示:
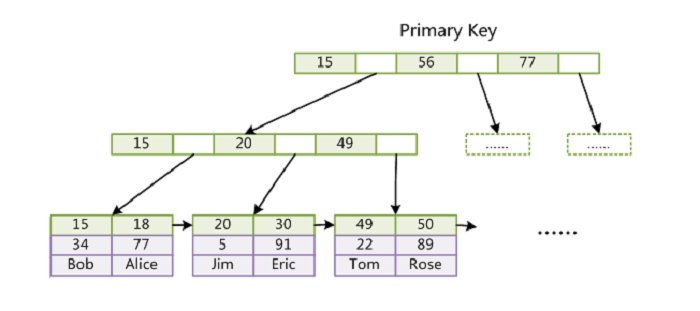
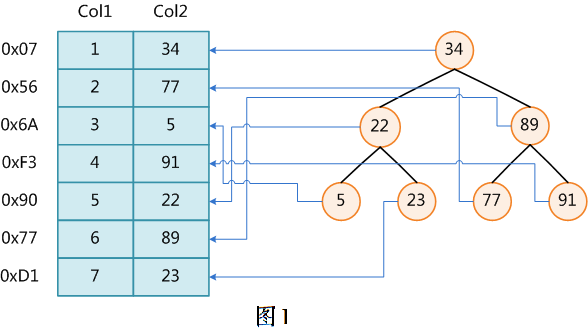
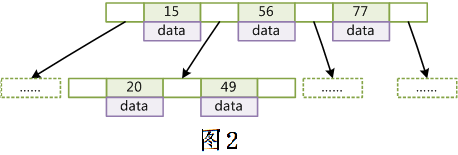
本文以 MySQL 数据库为研究对象,讨论与数据库索引相关的一些话题。特别需要说明的是, MySQL 支持诸多存储引擎,而各种存储引擎对索引的支持也各不相同,因此 MySQL 数据库支持多种索引类型,如 BTree 索引,哈希索引,全文索引等等。为了避免混乱,本文将只关注于 BTree 索引,因为这是平常使用 MySQL 时主要打交道的索引,至于哈希索引和全文索引本文暂不讨论。
文章主要内容分为三个部分。
第一部分主要从数据结构及算法理论层面讨论 MySQL 数据库索引的数理基础。
第二部分结合 MySQL 数据库中 MyISAM 和 InnoDB 数据存储引擎中索引的架构实现讨论聚集索引、非聚集索引及覆盖索引等话题。
第三部分根据上面的理论基础,讨论 MySQL 中高性能使用索引的策略。
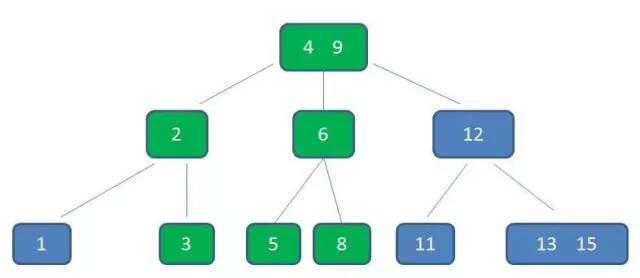
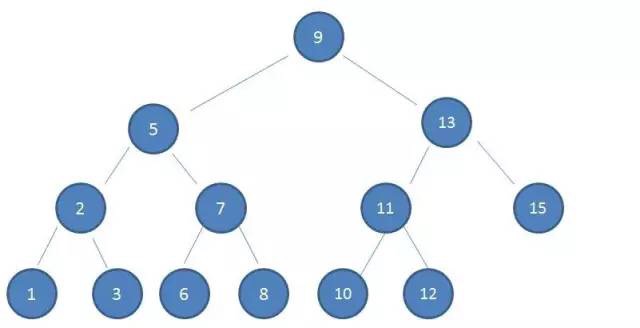
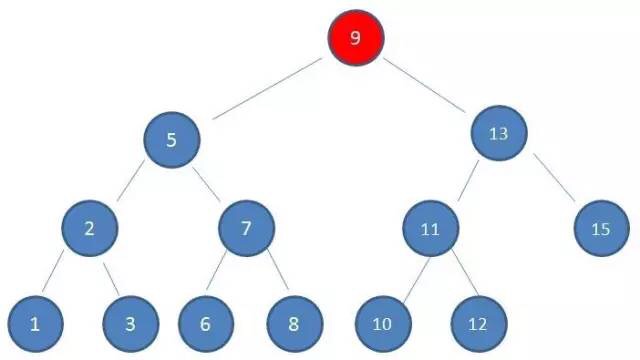
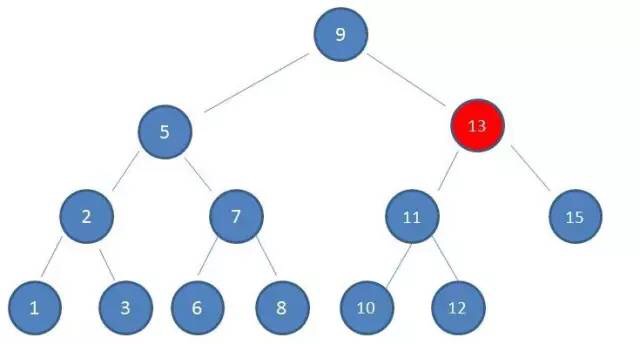
数据结构及算法基础
索引的本质
MySQL 官方对索引的定义为:索引(Index)是帮助 MySQL 高效获取数据的数据结构。提取句子主干,就可以得到索引的本质:索引是数据结构。
MySQL 的优化主要分为结构优化(Scheme optimization)和查询优化(Query optimization)。本章讨论的高性能索引策略主要属于结构优化范畴。本章的内容完全基于上文的理论基础,实际上一旦理解了索引背后的机制,那么选择高性能的策略就变成了纯粹的推理,并且可以理解这些策略背后的逻辑。
示例数据库
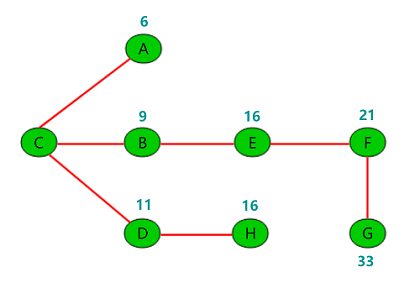
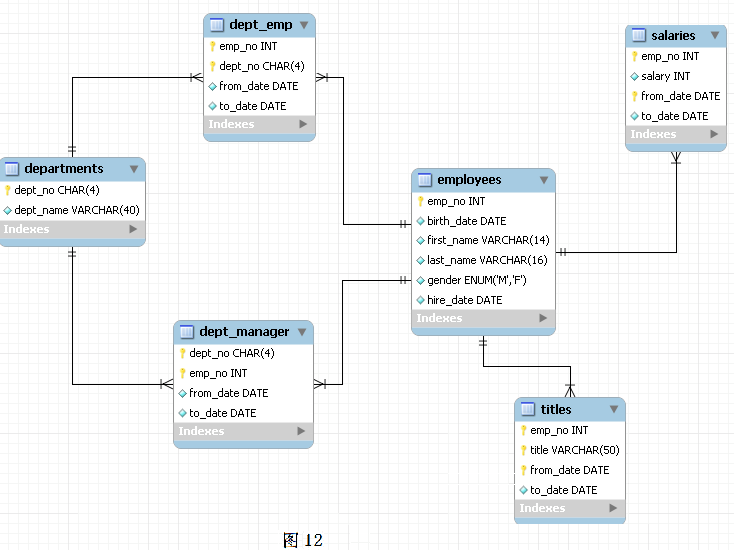
为了讨论索引策略,需要一个数据量不算小的数据库作为示例。本文选用 MySQL 官方文档中提供的示例数据库之一:employees。这个数据库关系复杂度适中,且数据量较大。下图是这个数据库的 E-R 关系图(引用自 MySQL 官方手册):
EXPLAIN SELECT*FROM employees.titlesWHERE emp_no='10001'AND title IN ('Senior Engineer', 'Staff', 'Engineer', 'Senior Staff', 'Assistant Engineer', 'Technique Leader', 'Manager')AND from_date='1986-06-26'; +----+-------------+-------+---------+---------+------+------+-------------+ | id | select_type | type | key | key_len |ref|rows| Extra | +----+-------------+-------+---------+---------+------+------+-------------+ |1| SIMPLE |range|PRIMARY|59|NULL|7|Usingwhere| +----+-------------+-------+---------+---------+------+------+-------------+
这次 key_len 为 59,说明索引被用全了,但是从 type 和 rows 看出 IN 实际上执行了一个 range 查询,这里检查了 7 个 key。看下两种查询的性能比较:
SHOW PROFILES; +----------+---------------------------------------------------------------+ | Duration | Query | +----------+---------------------------------------------------------------+ |0.000580|SELECT*FROM employees.titles WHERE emp_no='10001'AND from_date='1986-06-26'| |0.000525|SELECT*FROM employees.titles WHERE emp_no='10001'AND title IN ... | +----------+---------------------------------------------------------------+
“填坑”后性能提升了一点。如果经过 emp_no 筛选后余下很多数据,则后者性能优势会更加明显。当然,如果 title 的值很多,用填坑就不合适了,必须建立辅助索引。
查询条件没有指定索引第一列
EXPLAIN SELECT*FROM employees.titles WHERE from_date='1986-06-26'; +----+-------------+------+------+---------+------+--------+-------------+ | id | select_type | type | key | key_len |ref|rows| Extra | +----+-------------+------+------+---------+------+--------+-------------+ |1| SIMPLE |ALL|NULL|NULL|NULL|443308|Usingwhere| +----+-------------+------+------+---------+------+--------+-------------+
由于不是最左前缀,索引这样的查询显然用不到索引。
匹配某列的前缀字符串
EXPLAIN SELECT*FROM employees.titles WHERE emp_no='10001'AND title LIKE'Senior%'; +----+-------------+-------+---------+---------+------+------+-------------+ | id | select_type | type | key | key_len |ref|rows| Extra | +----+-------------+-------+---------+---------+------+------+-------------+ |1| SIMPLE |range|PRIMARY|56|NULL|1|Usingwhere| +----+-------------+-------+---------+---------+------+------+-------------+
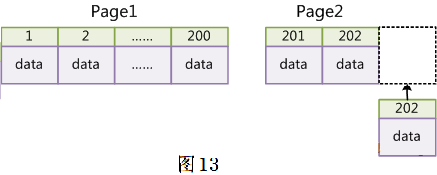
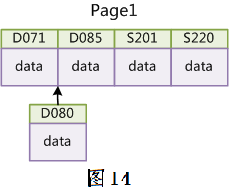
此时 MySQL 不得不为了将新记录插到合适位置而移动数据,甚至目标页面可能已经被回写到磁盘上而从缓存中清掉,此时又要从磁盘上读回来,这增加了很多开销,同时频繁的移动、分页操作造成了大量的碎片,得到了不够紧凑的索引结构,后续不得不通过 OPTIMIZE TABLE 来重建表并优化填充页面。
因此,只要可以,请尽量在 InnoDB 上采用自增字段做主键。
后记
这篇文章断断续续写了半个月,主要内容就是上面这些了。不可否认,这篇文章在一定程度上有纸上谈兵之嫌,因为我本人对 MySQL 的使用属于菜鸟级别,更没有太多数据库调优的经验,在这里大谈数据库索引调优有点大言不惭。就当是我个人的一篇学习笔记了。
其实数据库索引调优是一项技术活,不能仅仅靠理论,因为实际情况千变万化,而且 MySQL 本身存在很复杂的机制,如查询优化策略和各种引擎的实现差异等都会使情况变得更加复杂。但同时这些理论是索引调优的基础,只有在明白理论的基础上,才能对调优策略进行合理推断并了解其背后的机制,然后结合实践中不断的实验和摸索,从而真正达到高效使用 MySQL 索引的目的。
另外,MySQL 索引及其优化涵盖范围非常广,本文只是涉及到其中一部分。如与排序(ORDER BY)相关的索引优化及覆盖索引(Covering index)的话题本文并未涉及,同时除 B-Tree 索引外 MySQL 还根据不同引擎支持的哈希索引、全文索引等等本文也并未涉及。如果有机会,希望再对本文未涉及的部分进行补充吧。
参考文献
[1] Baron Scbwartz等 著,王小东等 译;高性能MySQL(High Performance MySQL);电子工业出版社,2010 [2] Michael Kofler 著,杨晓云等 译;MySQL5权威指南(The Definitive Guide to MySQL5);人民邮电出版社,2006 [3] 姜承尧 著;MySQL技术内幕-InnoDB存储引擎;机械工业出版社,2011 [4] D Comer, Ubiquitous B-tree; ACM Computing Surveys (CSUR), 1979 [5] Codd, E. F. (1970). “A relational model of data for large shared data banks”. Communications of the ACM, , Vol. 13, No. 6, pp. 377-387 [6] MySQL5.1参考手册 - http://dev.mysql.com/doc/refman/5.1/zh/index.html
]]>
<blockquote>
<p>原文:<a href="http://blog.codinglabs.org/articles/theory-of-mysql-index.html">http://blog.codinglabs.org/articles/theory-of-mysql-index.html</a></p>
</blockquote>
<p>本文以 MySQL 数据库为研究对象,讨论与数据库索引相关的一些话题。特别需要说明的是, MySQL 支持诸多存储引擎,而各种存储引擎对索引的支持也各不相同,因此 MySQL 数据库支持多种索引类型,如 BTree 索引,哈希索引,全文索引等等。为了避免混乱,本文将只关注于 BTree 索引,因为这是平常使用 MySQL 时主要打交道的索引,至于哈希索引和全文索引本文暂不讨论。<br><img src="//www.fanhaobai.com/2016/05/mysql-index/7d6b1a54-61dd-4ecb-9b84-b064ec95775a.png" alt="预览图">